






技术盛宴|浅谈AIGC算力网络中LPO模块的技术优势
有网络的地方就会有光模块的应用,那么算力网络中会部署哪种光模块呢?本文将围绕光模块失效率,分析传统DSP模块的主要失效原因,结合LPO技术进行失效率对比分析,讨论LPO模块的优势所在。






随着AI技术的迅猛发展,各式各样的AI应用走入大家的工作、学习和生活当中,比如Chatbot(聊天机器人)、虚拟主播、AIPC(人工智能个人电脑,Artificial Intelligence Personal Computer)等。为了让用户获取更好的应用体验,更快地响应时效要求,需要更好的大语言模型,更大规模的模型参数量。
相信大家也关注到,近期行业发布的Llama 3.1 模型,参数规模已达到惊人的4050亿。
如此庞大的模型训练离不开超大规模智算中心的支撑,近期马斯克在社交平台上宣布:xAI公司已经开始在超级计算中心的“Supercluster”进行训练,该集群由10万个液冷H100 GPU组成,10万张GPU算力卡的互联需要高速网络通道。
随着智算中心集群规模的不断扩张,光市场已经占据数据中心越来越多的份额。在100G时代,光模块和网络的比例约为1:1;到了400G时代,光模块和网络的比例变为7:3,光模块在集群中的重要性不言而喻。本文将围绕光模块失效率,分析传统DSP模块的主要失效原因,结合LPO技术进行失效率对比分析,讨论LPO模块的优势所在。
一、算力网络中光模块的现状
谈到光模块大家不会陌生,有网络的地方就会有光模块的应用。那么算力网络中会部署哪种光模块呢?
下图展示了目前智算中心RoCE以太网方案的主流网络架构,服务器端通过400G高速网卡接入到算力网络中,搭载51.2T交换芯片的数据中心交换机组成三级架构支撑万卡以上的集群规模。

不难看出智算中心对模块速率的要求已经到达了400G,交换机互联的部分甚至可以考虑采用800G互联。
目前主流51.2T的交换芯片是112G SerDes,因此交换机侧的400G光模块对应是Q112的封装,网卡侧目前主要是OSFP的封装,部署时根据距离选择对应长度的型号即可。

二、DSP光模块工作原理
以400G Q112 VR4模块为例分析DSP光模块的工作原理以及各部件的关键作用。(SR、DR模块结构图大致相同,只是所用的电光转换方案不同,SR用VCSEL,DR用EML或者硅光)
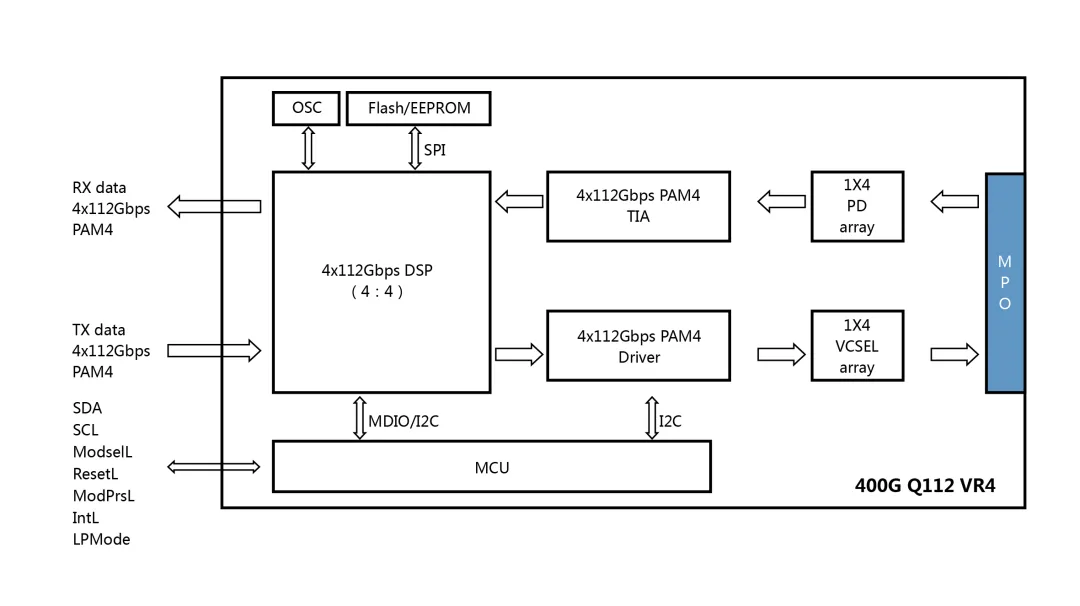
1、交换芯片发送4*112Gbps PAM4电信号进入光模块中
2、DSP芯片会将经过的电信号进行重整形然后发到Driver端
3、Driver作为驱动将电信号传输到激光器处
4、VCSEL激光器把电信号转光信号并发到光纤
5、光信号经过光纤到达对端光模块的PD光电二极管阵列后被转换成电信号
6、TIA将转换后的电信号进行信号放大并送到DSP芯片
7、DSP芯片再次将电信号进行重整型后发送到交换机芯片上
三、光模块失效率指标
失效率为何被关注
相较于交换机、服务器等设备,光模块的结构其实是比较简单的,但就是如此简单的光模块在算力网络中也是至关重要的存在。虽然单一模块的失效率比较低,但是放在万卡以上的集群中也会被放大数倍。模块的失效会造成一定概率的故障发生,故障又会导致训练业务的中断,重新启动训练需要额外的耗时,无形中增加了集群的运营成本。因此光模块的失效率需要被重视起来。
失效率指标定义
FIT(Failures In Time)失效率是一个衡量产品或系统在单位时间内发生故障的频率的指标。它通常用来描述在一定时间范围内,特定数量的产品或系统预计会出现多少次故障。FIT是一个无量纲值,表示的是每十亿小时内的故障次数。例如,如果一个产品在10亿小时内发生了100次故障,那么它的FIT失效率就是100 FIT。这表示在观察的时间段内,每十亿小时可以预期会发生100次故障。
光模块的失效率=模块中所有元器件失效率的求和,比如某个光模块的理论失效率=155.63FIT,意味着在十亿小时内可以预期会发生155.63次失效。
单一模块发生一次失效所需要的小时数量=10亿/155.63≈8647744(小时)换算成一个好理解的方式即为单个模块在8647744个小时内会出现一次失效,单看这个数据感觉模块的可靠性非常高,但放在整个集群中我们来看看具体数据。

如图所示,我们列举了不同集群规模下所需要的光模块数量以及所有光模块发生一次模块失效的间隔时间,不难看出这是一个随着模块数量变大而单调递减的函数。
单一模块的失效率在万卡以上的集群规模中被放大了,理论上在32K卡的集群中大概每两天就会发生一次模块失效,这样来看模块的失效率还是相当值得关注的。
导致光模块失效率变化的主要因素
有两个主要因素会引起失效率变化,一个是模块内部的元器件数量,另一个是模块自身的工作温度。
具体变化关系是:
1、模块元器件越少,失效率越低
2、模块工作温度越低,失效率越低
传统DSP光模块失效率分析
传统DSP模块方案在失效率方面还存在以下缺陷:
1、模块元器件多、工作温度高:DSP模块不仅有DSP芯片,还包括周边的晶体振荡器、Flash、电源等一系列芯片,且功耗占比超过50%,会显著提升模块的工作温度。
2、模块元器件本身失效率高:DSP模块如果采用EML或VCSEL方案,会包括多颗分离的III-V族激光器,而激光器本身的失效率就会偏高。
基于以上分析可以看到导致DSP模块失效的主要原因是器件数量多、工作温度高,比如DSP及周边芯片、EML/VCSEL激光器等。要想降低模块的失效率还是得从根源解决问题,下面我们来介绍一下LPO(Linear-drive Pluggable Optics)模块方案。
四、LPO光模块解决方案
LPO模块
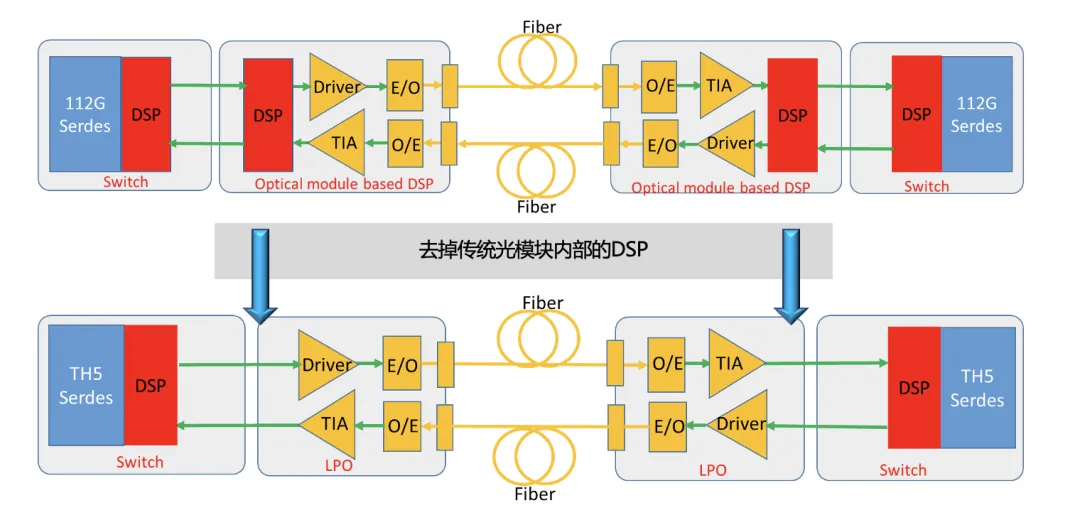
LPO 模块去掉了传统DSP模块中的DSP芯片,利用交换芯片中DSP进行电信号的处理,模块中采用常规性能的Driver和TIA芯片,并选用合适的电光转换方案,即可以实现优异的传输性能。电光转换部分可以采用VCSEL、EML或者硅光方案,硅光具有更好的线性度、更低的电反射。为了保障供应以及更高的可靠性,锐捷网络采用了硅光技术方案。更多LPO基础概念的介绍可以参考往期文章揭秘智算中心网络建设新利器:LPO技术的出现。
LPO模块失效率分析


上述图表展示了400G模块在相同模块工作温度55°C情况下,不同技术方案的失效率比例关系。可以看到在相同模块工作温度下,LPO+硅光方案的失效率更低,其他方案失效率为LPO+硅光方案的1.31~2.34倍左右。
这样的对比方式是从理论上评估不同模块的失效率,因此会控制工作温度保持不变。而在实际部署中,LPO+硅光模块的工作温度相较于DSP方案会更低,因此失效率可以得到进一步的降低。

如上图所示,在相同的环境温度情况下,LPO模块的工作温度比DSP模块要低15°C左右。

结合上述图表,可以看到LPO模块温度从55°C降低到40°C后,失效率下降了50%,具备更高的可靠性。

从实际部署场景来看,将不同技术方案的400G模块放在相同环境温度下进行对比,能够看到LPO+硅光方案的失效率得到进一步降低,这就是模块工作温度较低带来的收益。
总结
基于以上理论分析结合实际数据来看,LPO+硅光的方案相较于其他方案而言失效率是较低的。核心原因在于以下两点:
1、移除DSP芯片:去掉DSP芯片后可以较大幅度降低模块工作温度,降低因高温给激光器带来的影响。
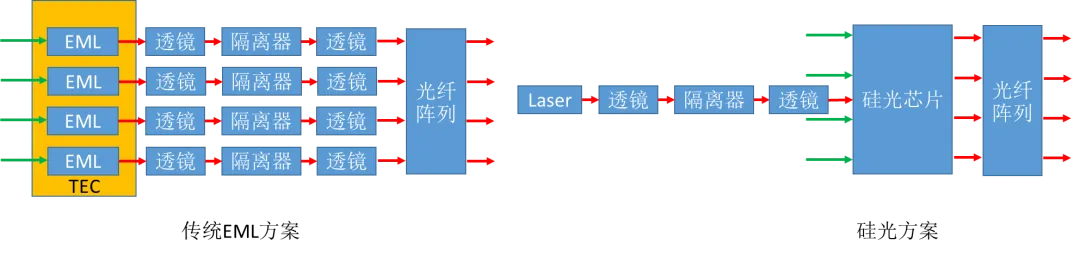
2、采用硅光技术:如下图所示,光电转换部分采用硅光方案后可以让硅光芯片负责信号调制,Laser仅需要提供直流光,无需调制信号。对比EML方案需要4个激光器以及TEC,硅光方案的Laser只需要1个,减少了模块元器件的数量,降低失效率。
五、LPO光模块性能参数
只具备更低的模块失效率还不足以让LPO模块替代DSP模块,我们还应评估光模块的可用性,也就是关注BER(误码率)和SEN(灵敏度),这两个指标的性能参数需要能达到协议门限的标准。
光模块BER&SEN评估方法
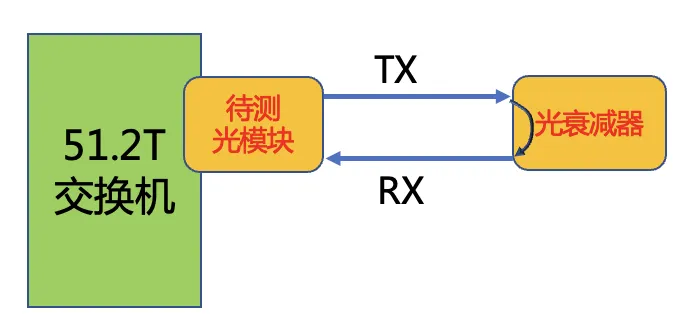
通过调节光衰减的大小,得到不同RX光功率下的BER,将所有测试结果汇总到一起绘制成BO曲线。

当光功率一直调小(图表中横坐标向左调整趋势),直到BER等于FEC门限规定的2.4e-4(图表中纵坐标向上调整趋势)时,记录此时的光功率就是光模块的灵敏度(SEN)。通常的BER都是在没有加光衰减器的情况下测试的,即在BER error floor区间测试的结果。
SEN越小说明光模块越能容忍更小的光功率,对实际的部署有比较大的帮助,比如由于接头脏污、发端光功率变小、光纤接头插损大等会造成光功率变小的情况。
LPO DR模块的性能参数
以下是不同方案模块在常温短纤场景中的测试数据

从BER图表数据可以看到以下现象:
1、LPO DR模块的BER和协议门限相比有5个数量级的余量。
2、LPO DR与DSP+硅光方案的BER参数接近,且优于DSP+EML方案 2~3个数量级。

从SEN图表数据看到以下现象:
1、LPO DR模块的SEN和协议门限相比有3.5dB的左右余量。
2、三种方案在SEN参数方面相差不大。
基于以上现象可以得出结论:LPO+硅光性能参数接近DSP+硅光,优于DSP+EML方案,因此可以替代现有的DSP DR方案。
六、LPO光模块的其他收益
LPO光模块除了高可靠性及高可用性这两点外,在其他维度也具备一定的价值收益。
1、更低功耗:去掉DSP芯片后,光模块的最大功耗可以降低51.3%左右,低于4W(壳温70℃测试)。

2、更低时延:模块中少了DSP芯片,减少一跳,时延可以降低95%,满足更低延迟的应用场景。

3、良好供应:传统DSP模块的DSP芯片和VCSEL激光器目前供应比较紧张,且交期比较长,大规模交付有供应风险。LPO模块方案去掉了DSP芯片,并且采用硅光技术,避免使用供应紧张的DSP芯片和VCSEL芯片,在一定程度上规避了关键器件的供应风险。
七、锐捷LPO光模块产品


锐捷网络聚焦AIGC算力网络场景规划设计了三款LPO DR的自研光模块,满足以下三种网络架构的互联需求。

目前正在配合各大厂进行适配测试工作,敬请期待。
锐捷网络,作为GenAI时代的全栈服务专家,致力于为企业提供覆盖IaaS到PaaS的全栈产品及解决方案。我们的产品覆盖高性能网络与GPU算力优化调度,旨在通过创新技术解决方案,帮助客户实现生产效率的飞跃与运营成本的优化。我们坚信,通过我们的努力,能够为客户打造一个更加智能、高效和可靠的未来。让我们携手,共同探索AI时代的每一个机遇。
相关标签:


点赞


更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















