






技术盛宴 | 端侧链路故障逃生技术,破解万亿级大模型训练中断难题
针对万亿级大模型分布式训练中的端侧链路故障导致的训练中断与算力损失难题,锐捷网络推出基于NCCL的端侧链路故障逃生方案。该方案采用备份链路与非侵入式设计,实现毫秒级故障识别与秒级切换,保障训练连续不中断,有效降低AI训练集群的硬件故障成本与算力浪费。







背景
近年来,随着人工智能技术的迅猛发展,机器学习模型的规模呈现出爆发式增长态势。尤其在深度学习领域,模型规模的显著提高成为推动诸多技术突破与性能提升的关键要素。当模型参数数量达到万亿级别时,受限于单台设备的物理资源而无法实现单机训练。为此,分布式训练技术应运而生,并迅速成为训练超大规模模型的核心手段。分布式训练能够显著提高训练效率,突破单机内存和计算能力的瓶颈。融合模型并行与数据并行等技术的分布式混合并行训练策略成为训练超大规模大语言模型的主要技术途径,该方法不仅能有效利用大规模硬件资源,还能在确保训练稳定性和模型性能的前提下,实现大语言模型的高效训练与部署。
一、网络故障
分布式训练是指在多个计算节点上协同作业,共同完成机器学习模型的训练过程。通过将训练任务拆分至多个设备上并行执行,不仅能合理分配计算和存储资源,也能显著提升训练速度,并且能够处理更大规模的数据和模型。
然而,训练过程中出现故障的可能性会随着训练规模和持续时间的增加而升高。一旦发生故障,将使所有参与的设备处于闲置状态,直至故障设备恢复正常,导致大量算力无法得到充分利用。来自Meta、HuggingFace和LAION的团队均报告了在训练大型模型时因失败导致利用率严重下降的情况。
根据Meta团队训练Llama3.1的报告,在训练期间平均每三个小时就会发生一次故障,其中约8.4%的故障是由网络设备故障导致的。不同于其他由软件引发的故障,网络设备故障大多为硬件故障,例如网络线缆或是网卡光模块等硬件设备出现故障。相较于软件故障,硬件故障的处理难度大、恢复时间长,可能造成更大的算力损失。
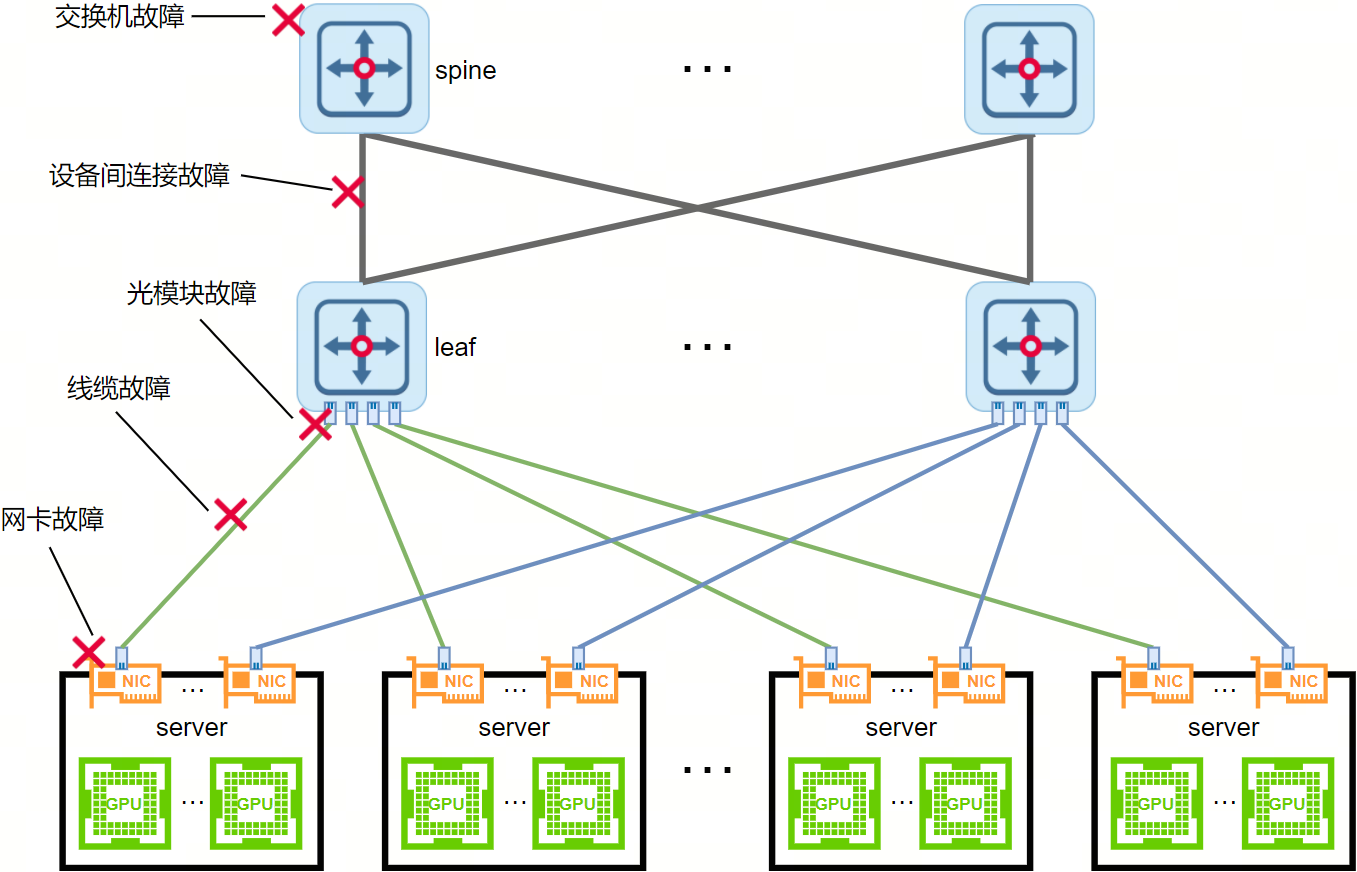
交换机设备间链路故障目前已能够实现毫秒级处理与收敛,但端侧网络设备故障目前尚无较为高效的处理方案。端侧设备故障主要包括服务器网卡故障、服务器与交换机的连接线缆损坏以及线缆光模块故障等。随着计算集群规模持续扩大,端侧网络设备故障已成为亟待解决的问题。
二、故障处理
目前,除软件故障外,硬件故障的处理策略通常不区分具体的故障类型,发生硬件故障时,通常采用相同的方案进行处理。
检查点(Checkpoint)是一种常见的持久化机制,用于保存训练进度。在故障发生后,系统会立即对故障设备进行修复,或者将故障设备从集群中剔除,然后从最近的检查点加载模型并继续训练。目前,许多优化策略围绕检查点机制展开:
1.EasyCkpt 采用异步化、层次化的保存方式,结合重叠模型拷贝与计算、网络感知的异步存储策略,实现了近乎零开销的模型保存机制,并保证了大模型训练过程中模型保存与恢复的精度无损。
2.Gemini 能够将 Checkpoint 保存在具有更大聚合带宽的 CPU 内存中,并通过一系列方案实现了大型模型训练的快速故障恢复。
尽管如此,仍无法完全避免因故障定位和模型训练重启所带来的算力损失。
冗余计算(Redundant computation)可以避免重新配置和重新启动的开销,在进行模型训练时使用不同的节点进行冗余计算。当某个节点发生故障时,其他节点能够代替故障节点进行计算,但是这样引入了固定的内存开销和计算开销,进一步增加了训练成本。
三、锐捷网络的端侧链路故障逃生
锐捷网络的端侧链路故障逃生是一种基于NCCL(NVIDIA Collective Communications Library)实现的端侧链路故障快速规避方案,能够在上层训练框架无感知的情况下,自动对端侧链路故障进行识别并处理,在模型训练过程中发生端侧链路故障时能够保持训练不中断,在故障设备完成修复后训练性能自动恢复。
端侧故障逃生方案通过在NCCL加入故障识别以及故障规避机制,并在创建数据链路时同步创建备份链路来处理由于硬件故障导致单条链路无法通信的问题。
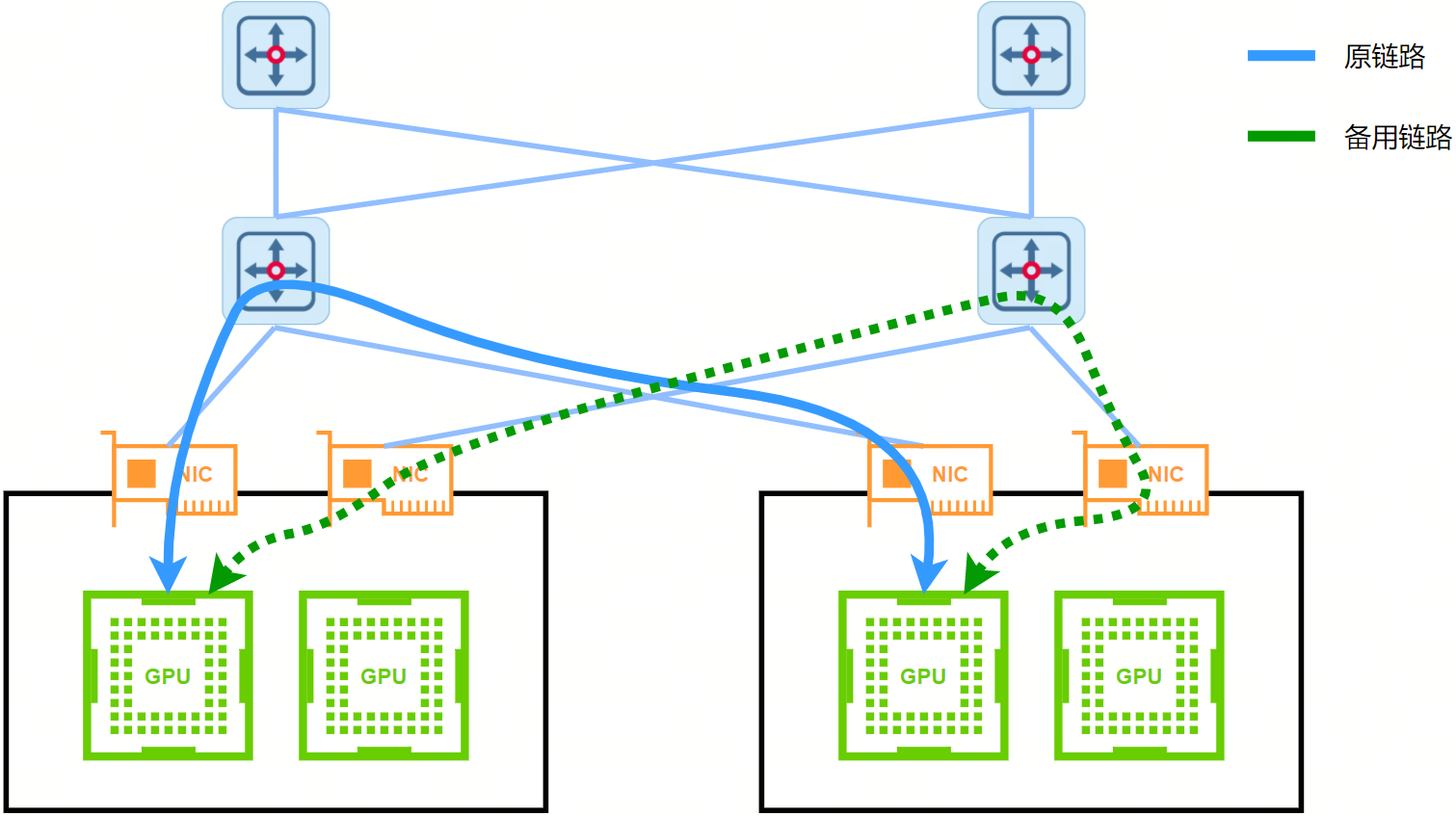
备份链路在主链路状态正常时不会进行数据传输,对传输效率不产生任何影响。而在出现端侧链路故障之后,通过一系列切换机制将原链路上的通信任务转移到备份链路进行传输。
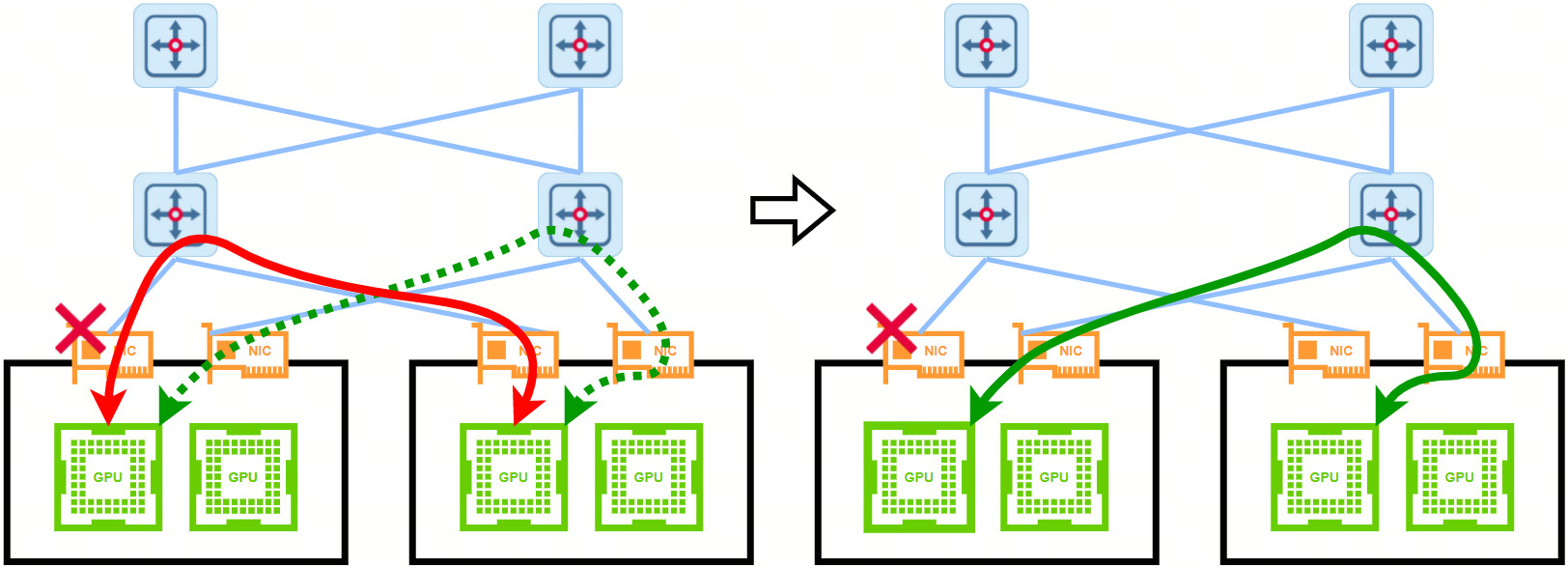
锐捷网络的端侧链路故障逃生方案具有以下主要特性:
1.非侵入式
该方案不受特定训练框架的限制,也无需对上层框架进行修改。故障发生后,由NCCL自行处理,上层框架无感知。
2.快速且可靠
能够对端侧链路故障进行毫秒级的识别与定位,并对故障链路上的通信任务进行快速迁移,可实现秒级收敛,并能保障通信任务不中断。
3.可恢复性
实时监测设备状态,若故障设备状态恢复正常,能够在恢复的设备上重建通信链路,并将其重新纳入通信设备集群。
锐捷网络的端侧链路故障逃生方案具有以下几点关键收益:
1.提升系统可靠性
使用端侧故障逃生方案能够有效避免因端侧网卡光膜线缆等设备发生故障而引起的训练业务中断,实现断链不断训,通信的可靠性提升10倍。
2.降低训练成本
能够有效避免训练集群因端侧链路故障而导致的算力资源浪费,同时基于自动故障恢复处理机制确保网络设备实现最大利用率,从而显著降低训练成本。 依据Meta公布的训练日志(Llama 3.1,405B模型),在为期54天的预训练阶段,共出现419次意外中断情况,其中约8.4%是由网络故障所致。H100的算力建设费用约为10元/卡/小时,若每次中断恢复需耗时1小时,那么万卡集群每次训练因网络故障造成的算力损失约为350万元。通过端侧链路故障逃生机制,每年可挽回上千万元的损失。
总结
大模型分布式训练过程中的端侧网络故障,这是影响模型训练的重大阻碍。构建精准且高效的故障处理机制,是各大型模型训练团队的持续追求,也是保障大模型训练的重要环节。
通过在通信库中添加故障处理模块,能够大幅度减少端侧链路故障导致的算力损失。随着方案的持续迭代与完善,我们坚信端侧故障逃生方案能够在大规模集群训练故障处理中发挥更为重要的作用,为客户创造更大的价值。锐捷网络,致力做最懂端侧的网络供应商!
相关标签:


点赞


更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















