






浅谈MoE技术的引入对机间通信带宽的影响
技术革新的浪潮涌来,MoE技术的出现为机器学习和深度学习领域注入了新的活力,与此同时,对智算中心网络带来了新的挑战。






随着人工智能技术的飞速发展,大语言模型(LLM)已成为自然语言处理领域的热门话题。而在这场技术革新的浪潮中,MoE(Mixture of Experts)技术凭借其独特的优势,为LLM训练注入了新的活力。然而,在实际应用部署中,MoE 技术对智算中心网络带来不小的挑战。本文主要介绍了MoE技术的诞生背景原理、应用领域,讨论了其对智算中心网络带来的挑战。
MoE诞生背景
MoE技术,即“Mixture of Experts”(专家混合系统),起源于1991年Michael I. Jordan和Robert A. Jacobs所撰写的论文《Hierarchical Mixtures of Experts and the EM Algorithm》。这篇在神经信息处理系统(Neural Information Processing Systems,简称NIPS)会议上发表的论文,被公认为机器学习领域的重要里程碑。
在该论文中,Jordan和Jacobs介绍了一种新颖的神经网络结构——“层次化专家混合系统”Hierarchical Mixtures of Experts)。其核心思想在于将复杂任务细分为多个子任务,并分别交由特定的“专家模型”进行处理。这种架构集成了多个专家模型以及一个门控模型;门控模型负责根据输入的数据特征,选择最适合的专家模型来应对特定任务。
MoE技术的问世为机器学习和深度学习领域注入了新的活力,特别是在处理包含多个子问题或需要融合多领域知识的复杂任务时,MoE技术展现出了其卓越的性能和独特的优势。
MoE技术原理
MoE的技术原理基于一种分而治之的策略,将复杂问题分解为多个较简单的子问题,并为每个子问题训练一个专门的模型(专家)。这些专家模型各自负责处理输入数据的一个子集或一种特定的情况。为了动态地整合这些专家的输出并生成最终预测或决策,MoE引入了一个门控网络(Gating Network)。
1)专家模型:
确定专家的数量和类型。每个专家通常是一个较小的神经网络,专门用于处理数据的一个子集或一个特定的任务。专家网络的设计可以根据任务需求进行定制,例如,使用全连接层、卷积层、循环层等。
2)门控模型:
门控模型是一个用于决定哪些专家应该参与到当前输入数据处理中的机制。它通常也是一个较小的神经网络,其输出是一个概率分布,表示每个专家对当前输入的重要性。门控模型的输入可以是原始输入数据的一个子集或全部,或者是专家模型的中间输出。
技术原理
当一个输入数据进入MoE系统时,首先通过门控网络计算出每个专家的激活概率。然后,每个专家网络基于输入数据进行前向传播,产生输出。
将所有专家的输出根据门控网络的激活概率进行加权组合,得到最终的模型输出。这种组合可以是简单的加权平均,也可以是更复杂的组合策略。
MoE技术应用领域
目前MoE技术在诸多场景中得到了广泛的应用部署:
1)自然语言处理:在机器翻译、情感分析等自然语言处理任务中,MoE可以集成多个模型,从而提高文本理解和生成的质量和准确性。
2)图像识别和计算机视觉:在图像分类、物体检测和图像生成等计算机视觉任务中,MoE能够结合多个专家模型的特点,提升模型对图像的表征和理解能力。
3)推荐系统:在个性化推荐和广告投放等领域,MoE可以将多个推荐模型组合起来,提供更准确和个性化的推荐结果,提高用户满意度和商业价值。
MoE技术对网络的挑战
即使MoE技术有诸多技术优势,但实际应用部署起来对智算中心网络还是存在不小的挑战。
由于专家模型的并行化和分布式训练的需求,每个专家可能需要处理所有输入数据的一部分,并且它们的输出需要被汇总以生成最终结果,这种信息交换的模式就会引入机间all-to-all的通信。
引入all-to-all通信的具体原因有以下几点:
1)专家间的数据交换:在MoE系统中,每个专家可能需要访问来自其他专家的信息,以便门控网络可以决定每个专家的激活程度。这通常涉及到所有专家之间的数据交换,即all-to-all通信。
2)并行训练:在分布式训练环境中,不同的专家可能被放置在不同的计算节点上。为了训练效率,每个节点上的专家需要快速交换数据,这也需要通过all-to-all通信来实现。
3)模型并行性:当专家模型变得非常大时,可能需要将一个专家模型拆分到多个计算节点上。这样,同一个专家模型的各个部分需要在节点之间进行通信,以保持模型的一致性和正确性。
4)减少计算瓶颈:all-to-all通信可以帮助减少单个节点的计算瓶颈,因为它允许并行处理和交换数据。这种通信模式可以最大化地利用计算资源,提高训练效率。
然而,all-to-all通信也带来了一些挑战,如增加网络带宽的需求、通信延迟和潜在的网络拥塞。因此,在实际应用中,需要仔细设计通信策略和优化网络拓扑,以确保高效的分布式训练和推理。
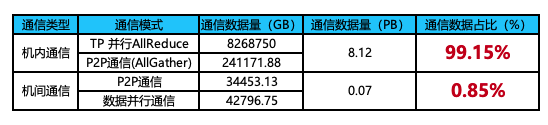
不引入MoE时的通信数据量
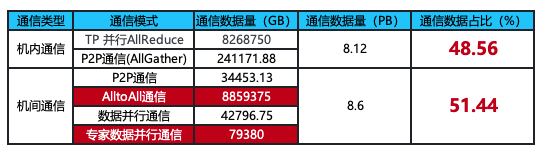
引入MoE后的通信数据量
通过网上获取到的公开信息对GPT4进行建模,在引入16个MoE专家层后,机间通信数据量与机内通信数据量基本持平;而在不引入MoE专家时,机间通信数据量是远小于机内通信数据量的。由此可知:MoE技术的引入增加了机间通信的比例,机间通信的网络带宽性能变得愈发重要,AIGC智算中心网络的建设也成为大家关注的重点。(《IT影响中国2023:锐捷AI-FlexiForce智算中心网络解决方案荣获影响力解决方案奖》)
总结
MoE专家混合系统技术目前已被广泛应用于LLM训练场景中,该技术能够显著增强模型的泛化能力并提升运算效率。然而,正如每个技术都有其两面性一样,MoE技术在带来诸多好处的同时,也引入了大量机间all-to-all的通信需求,这无疑对机间网络性能构成了严峻挑战。
为了应对这一挑战,锐捷网络通过搭建高性能的智算中心网络,提升机间网络的带宽利用率来确保业务的高吞吐能力,缓解由MoE技术引入的大量通信需求对网络性能造成的压力。
在全球互联网流量不断增长和数据应用需求日益多样化的背景下,作为AIGC全栈服务专家,锐捷网络不仅致力于推动网络技术的进步和发展,更是秉承创新性地解决客户问题,较早推出AIGC智算中心网络整体方案服务客户。展望未来,通过持续的技术研发和产品创新,锐捷网络将继续为全球的数据中心提供更加高效、可靠、智能的网络解决方案,在AIGC时代,助力互联网企业及各行各业的快速发展。
相关标签:


点赞
相关方案及案例




更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















