






【第三十四期】大型数据中心网络路由协议选择
【网络路由协议选择】如何为数据中心三层组网选择合适的路由协议?本文聚焦于大型数据中心场景,力图给出确切的答案。






数据中心网络互联技术
为了满足数据中心虚拟机(Vm)、容器(Docker)之间大二层通信的需求,数据中心网络发展历程中出现了众多依托网络设备硬件实现的互联组网技术——例如借鉴路由协议实现的大二层组网技术:多链接透明互联(TRILL)、最短路径桥接(SPB) ;虚实结合的Overlay技术:可扩展虚拟局域网(VXLAN)、使用通用路由封装的网络虚拟化(NVGRE)等等。但由于技术的复杂性、设备能力的参差不齐,这些技术均没有在网络设备上得到大规模应用。
到今天,我们看到数据中心(IDC)网络返璞归真,与业务解耦,简单、可靠成为核心诉求,数据中心只需要提供简单、可靠的三层Underlay组网,二层Overlay网络更多依赖主机侧软件或智能网卡实现。
那么问题来了,如何为数据中心三层组网选择合适的路由协议?本文聚焦于大型数据中心场景,力图给出确切的答案。
IDC网络架构演进
经济基础决定上层建筑。同样的,数据中心(物理)网络架构很大程度上决定了路由协议的规划。关于架构的设计,推荐阅读《技术盛宴 | 互联网数据中心网络25G组网架构设计》。本文对IDC网络架构仅做简要介绍,目的在于理清基础架构与路由协议选择的关系。
传统数据中心网络架构
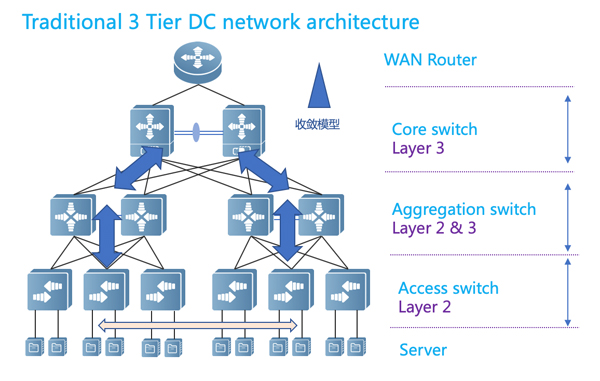
图1:传统数据中心网络架构(内部,不含网关区)
图1展示的是传统数据中心的网络架构:
传统IDC承载的大多是数据中心提供对外访问的业务;
流量分布符合80/20模型,且以南北向为主,东西向流量小;
网络架构设计采用核心-汇聚-接入三级结构,汇聚往下采用大二层组网,汇聚及核心横向采用厂商私有虚拟化技术,保证可靠性;
流量瓶颈在出口,IDC内部可以维持高收敛比(10:1甚至更大)。
近年来,随着云计算、大数据等业务的兴起,分布式计算、分布式存储等技术开始在IDC内部大规模部署。从网络视角看,IDC内部的东西向流量急剧上升,流量的80/20模型转变成以东西向流量为主。
此时,传统网络架构开始力所不逮,显现出诸多弊端:
扩展能力差:网络规模受限于核心交换机端口数量,无法平滑Scale-out(横向扩展);
收敛比过高:为南北向流量设计的流量模型,收敛模型呈三角型,越往上性能越低,东西向带宽严重不足;
单控制面运维复杂:汇聚及核心的可靠性依赖于厂商的横向虚拟化技术,虚拟化技术的单控制面存在明显弊端,很难做到不中断业务升级版本(ISSU ,In-Service Software Upgrade)。
Fabric网络架构
为解决传统IDC网络面临的问题,一种新的组网技术:Fabric网络架构,开始慢慢兴起。
Fabric一词,网工同学都不陌生:基于CLOS架构的机框式交换机,就是依赖于Fabric(交换网板)作为Line card(线卡)在设备内部的转发桥梁(如图2)。
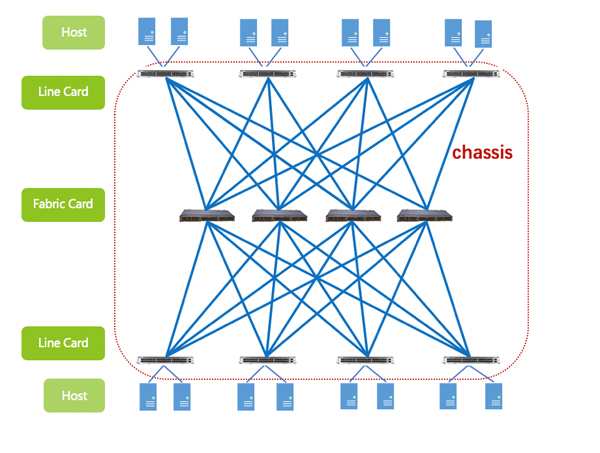
图2:IDC网络架构设计——Network as A Fabric
而时下数据中心火热的Fabric组网架构,与CLOS交换机有异曲同工之妙。
Line card:作为输入输出源,汇集所有服务器的流量,可以等同于IDC的柜顶交换机(TOR);
Fabric card:在中间层构建的高速转发通道,跨TOR流量通过Fabric进行高速转发。
把图2对折看,就是当下数据中心最流行的叶脊(Leaf-Spine)网络架构。
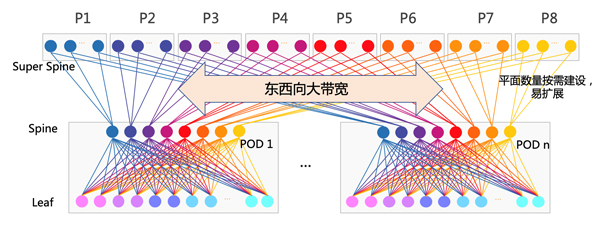
图3:Leaf-Spine叶脊网络架构
Leaf-Spine的两层结构,即可构成一个简单的叶脊网络。在IDC建设时,我们也会以最小交付单元(POD,Point Of Delivery)为单位进行网络建设。当然,为了提升这种网络架构的Scale-out能力,一般会在POD之上增加一层,用于横向连接各个数据中心POD,扩大整个数据中心集群的规模。
Leaf-Spine架构因其强大的Scale-out能力、极高的可靠性、出色的可运维能力而备受推崇。知名的全球互联网巨头,基本都使用了这种组网架构。
Fabric网络架构用什么路由协议?
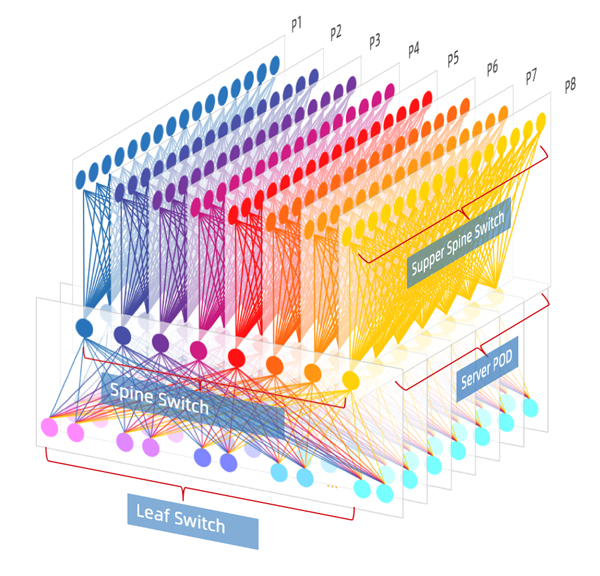
图4:利用Fabric构建的大型数据中心网络
Facebook在2014年开放了其数据中心网络设计(从F4演进到F16,但基本架构同图4):采用典型的Fabric网络。那么Fabric网络架构使用哪种路由协议更合适呢?
在RFC 7938《Use of BGP for Routing in Large-Scale Data Centers》中,作者提出了使用边界网关协议(BGP)作为数据中心内唯一路由协议的观点,并做了详细的分析,有兴趣的同学可以阅读RFC原文。
结合这篇RFC,以及当前国内外互联网公司的采用BGP组网的实践,我们分析下为什么BGP会更受青睐?
大型IDC网络路由设计原则
路由设计作为数据中心网络设计中非常重要的一环,其设计理念也需要和数据中心整体原则保持一致。有如下设计要点:
1、可扩展性
数据中心设计要点:大型互联网公司单园区最大服务器规模已经突破300K,很多大型园区服务器规模在20K到100K之间。数据中心网络在设计之初就需要考虑平滑的Scale-out能力,能按POD进行数据中心网络的交付(减少前期投入),并最终具备扩展到承载大规模、超大规模集群的能力。
路由协议设计要点:按照交换机和服务器数量1:20的比例(48口交换机,服务器双归网络典型的比例),超大型数据中心运营的网络设备数量是数以千计的。路由协议的设计需要考虑一致性,无论是初期的小规模,还是到上千万元构建的路由域,均能简单好用,能快速传播、收敛。
2、带宽和流量模型
数据中心设计要点:数据中心东西向流量爆发式增长,传统DC高收敛比模型已经无法满足东西向流量需求。新的网络架构中要尽可能地设计无收敛(Microsoft甚至部署了超速比网络,即上行带宽大于下行带宽)。考虑到网络建设的性价比,我们推荐部署每级收敛比1:1到3:1。
路由协议设计要点:对于Fabric网络,低收敛主要是依赖上行多链路负载来实现(例如典型的25G TOR交换机RG-S6510-48VS8CQ,其下行带宽48*25Gbps=1200Gbps,上行带宽8*100Gbps=800Gbps,端口全利用的情况下,收敛比为1.5:1)。对于数据中心路由设计,非常重要的一点,是能简单地在数据中心多链路之间实现等价多路径路由(ECMP)。在正常情况下,ECMP多链路可以均匀分担流量,链路新增或者剔除时,也能快速收敛而不影响现网业务。
3、CAPEX Minimization
数据中心设计要点:最大限度降低资本性支出。方法有:
尽量标准化网络设备的软硬件要求,基于统一架构减少设备类型;
简化网络特性要求,降低研发成本和时间成本。
路由协议设计要点:采用成熟的,通用的路由协议,并且需要在主流型号上支持,覆盖接入、核心、骨干设备。
4、OPEX Minimization
数据中心设计要点:最大限度降低运营成本。大型数据中心网络的运营成本往往会比基础设施的建设成本更高,减少运营成本也是架构设计之初就必须考虑的问题。
路由协议设计要点:减少网络中故障域的大小。
网络故障时,路由收敛影响面小,收敛时间快;
整个数据中心只使用一种路由协议:更好地简化运维,降低学习成本。运营知识库也可以更容易积累,帮助快速定位问题,恢复故障。
大型IDC网络路由协议选择
1、路由协议需要具备的能力
围绕前文分析的路由协议的设计要点,总结出大型IDC路由协议需要具备如下能力:
超大规模:考虑可扩展性,从建设之初到集群最终满配,都使用同样的协议组网,协议需要具备支撑横向扩展到“超大规模”数据中心的能力;
简单:选择足够简单、成熟、通用的路由协议,使用更少的软件特性,从而引入更多可供选择的设备厂商;
单一:数据中心尽量使用单一路由协议,降低复杂度,减少学习成本,也利于运营经验的积累;
减小故障域:当发生故障时,减少影响范围,提升网络的健壮性;
负载均衡:不依赖专用的负载均衡设备,在DC内部形成等价多路径;
灵活的策略控制:对于特定业务流需求,可提供丰富的路由策略控制手段;
快速收敛:在发生故障时,能减少影响面,快速收敛。
2、现有路由协议匹配度
我们看下现有路由协议的匹配度。
路由信息协议(RIP):不适用大规模数据中心;
增强内部网关路由协议(EIGRP):私有协议,不符合需求2、3;
内部BGP协议(IBGP):一般需要配合内部网关协议(IGP)一起使用,不满足需求2、3;
开放式最短路径优先(OSPF)、中间系统到中间系统(ISIS)、BGP:初步看这三种路由协议基本能满足1-7所有需求。其中ISIS和OSPF同属于链路状态IGP协议,相似度较高,选取应用更为广泛的OSPF进行对比。以下着重分析OSPF和BGP两种路由协议。
3、OSPF VS BGP
以下是维基百科对OSPF和BGP协议的定义。
OSPF:开放式最短路径优先(Open Shortest Path First),是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),运作于自治系统内部。采用戴克斯特拉算法(Dijkstra's algorithm)被用来计算最短路径树。它使用“代价(Cost)”作为路由度量。链路状态数据库(LSDB)用来保存当前网络拓扑结构,路由器上属于同一区域的链路状态数据库是相同的。
BGP:是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’(Prefix)表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。
OSPF和BGP都是应用非常广泛的路由协议,技术本身没有优劣之分。我们仅限于在大型/超大型的数据中心这个场景,来分析下两种路由协议适用度。
|
协议类型 对比项 |
OSPF |
BGP |
|
路由算法 |
Dijkstra algorithm |
Best path algorithm |
|
算法类型 |
链路状态 |
距离矢量 |
|
承载协议 |
IP |
TCP,有重传机制,保证了协议数据可靠性 |
|
需求一:大规模组网 |
适用度:★★★ 理论上无跳数限制,可以支持较大规模的路由组网;但OSPF需要定期整网同步链路状态信息,对于超大规模数据中心,链路状态信息库过大,网络设备计算时性能消耗大;同时网络震荡影响面大 |
适用度:★★★★★ 只传递计算好的最优路由信息 适用于大型/超大型数据中心,在超大规模园区已有成熟实践
|
|
需求二:简单 |
适用度:★★★ 部署简单,运维中等
|
适用度:★★★★ 部署简单、维护较简单
|
|
需求三:IDC内部署单一类型的路由协议 |
适用度:★★★★ 满足 IDC内部可以只部署OSPF单路由协议 在Server上也有丰富的软件支持 |
适用度:★★★★ 满足 IDC内部可以只部署BGP单路由协议 在Server上也有软件支持 外部自治系统之间也是使用BGP互联 |
|
需求四:减少故障域 |
适用度:★★ 域内要同步链路状态信息,所有的Failure需要同步更新 |
适用度:★★★★ BGP本地只传播计算好的最佳路径,当网络发生变化时,只传递增量信息 |
|
需求五:负载均衡 |
适用度:★★★★ 规划好COST值,多链路时形成ECMP,某一链路故障时需要同步域内设备计算
|
适用度:★★★★★ 规划好跳数、AS后,多链路时可形成ECMP,某一链路故障时将链路对应的下一跳从ECMP组内移除 |
|
需求六:灵活控制 |
适用度:★★★ 利用Area、lSA类型进行路由传播的控制,相对复杂
|
★★★★ 利用丰富的选路原则,对路由进行过滤、控制路由的收、发 |
|
需求七:收敛快 |
适用度:★★★ 路由数量少时,通过BFD联动可实现毫秒级收敛 通告的是链路状态信息,路由域大时,计算消耗大导致收敛会变慢 |
适用度:★★★★ 路由数量少时,通过BFD联动可实现毫秒级收敛 通告的是本地计算好的路由,路由域大也不会明显影响性能;同时BGP有基于AS的快速切换技术 |
表1 大型数据中心路由协议对比
通过上表分析,结合业界的一些实践,我们认为在中小型数据中心,路由域内网络设备数量不多的情况下,使用OSPF协议是比较合适的;而对于大型/超大型的数据中心,BGP的适用度会更高一些,建议部署BGP路由协议。
写在最后
限于篇幅原因,本文只介绍了大型IDC首选BGP路由协议组网的原因,并未涉及BGP协议具体规划。锐捷网络在国内TOP3的互联网公司,均承建了大型/超大型数据中心网络,且使用BGP路由协议组网。关于BGP路由协议的具体规划,这里先抛出几个问题,期待后续与大家共同探讨:
BGP私有AS号数量有限,对于大型数据中心,AS应该如何规划?
BGP使用什么接口建立邻居?ECMP/LACP场景下如何规划?
BGP选路原则非常多,怎么合理利用?
BGP性能、可靠性、收敛速度有哪些优化的方法?
本期作者:颜晓波
锐捷网络互联网系统部行业咨询

往期精彩回顾
- 【第一期】浅谈物联网技术之通信协议的纷争
- 【第二期】如何通过网络遥测(Network Telemetry)技术实现精细化网络运维?
- 【第三期】畅谈数据中心网络运维自动化
- 【第四期】基于Rogue AP反制的无线安全技术探讨
- 【第五期】流量可视化之ERSPAN的前世今生
- 【第六期】如何实现数据中心网络架构“去”堆叠
- 【第七期】运维可视化之INT功能详解
- 【第八期】浅析RDMA网络下MMU水线设置
- 【第九期】第七代无线技术802.11ax详解
- 【第十期】数据中心自动化运维技术探索之交换机零配置上线
- 【第十一期】 浅谈数据中心100G光模块
- 【第十二期】数据中心网络等价多路径(ECMP)技术应用研究
- 【第十三期】如何为RDMA构建无损网络
- 【第十四期】基于EVPN的分布式VXLAN实现方案
- 【第十五期】数据中心自动化运维技术探索之NETCONF
- 【第十六期】一文读懂网络界新贵Segment Routing技术化繁为简的奥秘
- 【第十七期】浅谈UWB(超宽带)室内定位技术
- 【第十八期】PoE以太网供电技术详解
- 【第十九期】机框式核心交换机硬件架构演进
- 【第二十期】 IPv6基础篇(上)——地址与报文格式
- 【第二十一期】IPv6系列基础篇(下)——邻居发现协议NDP
- 【第二十二期】IPv6系列安全篇——SAVI技术解析
- 【第二十三期】IPv6系列安全篇——园区网IPv6的接入安全策略
- 【第二十四期】Wi-Fi 6真的很“6”(概述篇)——不只是更高的传输速率
- 【第二十五期】 Wi-Fi 6真的很“6”(技术篇) ——前方高能,小白慎入
- 【第二十六期】IPv6系列应用篇——数据中心IPv4/IPv6双栈架构探讨
- 【第二十七期】你不可忽视的园区网ARP安全防护
- 【第二十八期】企业办公网接入认证技术详解
- 【第二十九期】互联网数据中心网络25G组网架构设计
- 【第三十期】数据中心网络运维的"巨人之剑"
- 【第三十一期】了解gRPC技术,这一篇就够了
- 【第三十二期】你真的足够了解Wi-Fi吗?
- 【第三十三期】关于自动化仓储Wi-Fi网络无缝漫游设计
- 【第三十四期】大型数据中心网络路由协议选择
相关推荐:
相关标签:


点赞



,RG-S6510-48VS8CQ")




更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















