












RDMA(远程直接数据存取),以其对业务带来的高性能、低延时优势,在数据中心尤其是AI、HPC、大数据等场景得到了广泛应用。为保障RDMA的稳定运行,基础网络需要提供端到端无损零丢包及超低延时的能力,这也催生了PFC、ECN等网络流控技术在RDMA网络中的部署。在RDMA网络中,如何合理设置MMU(缓存管理单元)水线是确保RDMA网络无损和低延时的关键。本文将以RDMA网络作为切入点,结合实际部署经验,分析MMU水线设置的一些思路。
什么是RDMA?
RDMA(Remote Direct Memory Access),通俗的说就是远程的DMA技术,是为了解决网络传输中服务器端数据处理的延迟而产生的。
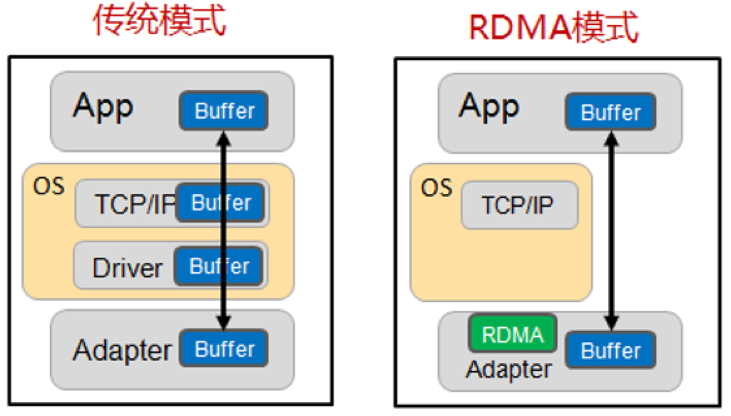
▲ 传统模式与RDMA模式工作机制对比
如上图,在传统模式下,两台服务器上的应用之间传输数据,过程是这样的:
- 首先要把数据从应用缓存拷贝到Kernel中的TCP协议栈缓存;
- 然后再拷贝到驱动层;
- 最后拷贝到网卡缓存。
多次内存拷贝需要CPU多次介入,导致处理延时大,达到数十微秒。同时整个过程中CPU过多参与,大量消耗CPU性能,影响正常的数据计算。
在RDMA 模式下,应用数据可以绕过Kernel协议栈直接向网卡写数据,带来的显著好处有:
- 处理延时由数十微秒降低到1微秒内;
- 整个过程几乎不需要CPU参与,节省性能;
- 传输带宽更高。
RDMA对于网络的诉求
RDMA在高性能计算、大数据分析、IO高并发等场景中应用越来越广泛。诸如iSICI, SAN, Ceph, MPI, Hadoop, Spark, Tensorflow等应用软件都开始部署RDMA技术。而对于支撑端到端传输的基础网络而言,低延时(微秒级)、无损(lossless)则是最重要的指标。
低延时
网络转发延时主要产生在设备节点(这里忽略了光电传输延时和数据串行延时),设备转发延时包括以下三部分:
- 存储转发延时:芯片转发流水线处理延迟,每个hop会产生1微秒左右的芯片处理延时(业界也有尝试使用cut-through模式,单跳延迟可以降低到0.3微秒左右);
- Buffer缓存延时:当网络拥塞时,报文会被缓存起来等待转发。这时Buffer越大,缓存报文的时间就越长,产生的时延也会更高。对于RDMA网络,Buffer并不是越大越好,需要合理选择;
- 重传延时:在RDMA网络里会有其他技术确保不丢包,这部分不做分析。
无损
RDMA在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。在传统网络模式下,要想实现不丢包最主要的手段就是依赖大缓存,但如前文所说,这又与低延时矛盾了。因此,在RDMA网络环境中,需要实现的是较小Buffer下的不丢包。
在这个限制条件下,RDMA实现无损主要是依赖基于PFC和ECN的网络流控技术。
• RDMA无损网络的关键技术:PFC
PFC(Priority-based Flow Control),基于优先级的流量控制。是一种基于队列的反压机制,通过发送Pause帧通知上游设备暂停发包来防止缓存溢出丢包。
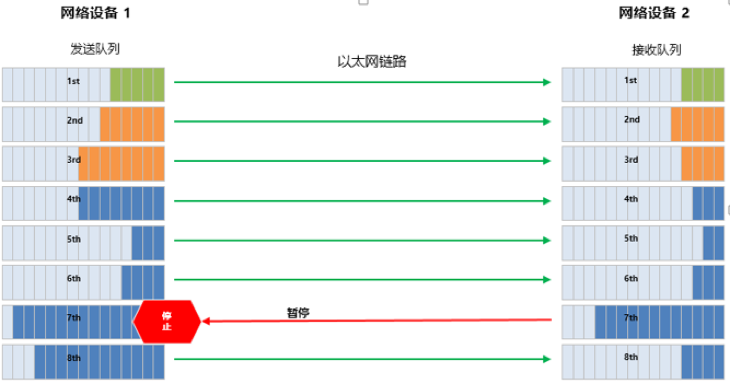
▲ PFC工作机制示意图
PFC允许单独暂停和重启其中任意一条虚拟通道,同时不影响其它虚拟通道的流量。如上图所示,当队列7的Buffer消耗达到设置的PFC流控水线,会触发PFC的反压:
- 本端交换机触发发出PFC Pause帧,并反向发送给上游设备;
- 收到Pause帧的上游设备会暂停该队列报文的发送,同时将报文缓存在Buffer中;
- 如果上游设备的Buffer也达到阈值,会继续触发Pause帧向上游反压;
- 最终通过降低该优先级队列的发送速率来避免数据丢包;
- 当Buffer占用降低到恢复水线时,会发送PFC解除报文。
• RDMA无损网络的关键技术:ECN
ECN(Explicit Congestion Notification):显示拥塞通知。ECN是一个非常古老的技术,只是之前使用的并不普遍,该协议机制作用于主机与主机之间。
ECN是报文在网络设备出口(Egress port)发生拥塞并触发ECN水线时,使用IP报文头的ECN字段标记数据包,表明该报文遇到网络拥塞。一旦接收服务器发现报文的ECN被标记,立刻产生CNP(拥塞通知报文),并将它发送给源端服务器,CNP消息里包含了导致拥塞的Flow信息。源端服务器收到后,通过降低相应流发送速率,缓解网络设备拥塞,从而避免发生丢包。
通过之前的描述可以了解到,PFC和ECN之所以可以实现网络端到端的零丢包,是通过设置不同的水线来实现的。对这些水线的合理设置,就是针对交换机MMU的精细化管理,通俗讲就是对交换机Buffer的管理。接下来我们具体分析下PFC的水线设置。
PFC水线设置
交换芯片都有固定的Pipeline(转发流水线), Buffer管理处于入芯片流程和出芯片流程的中间位置。报文处于在这个位置上时,已经知道了该报文的入口和出口信息,因此逻辑上就可以分成入方向和出方向分别对缓存进行管理。
PFC水线是基于入方向缓存管理进行触发的。芯片在入口方向提供了8个队列,我们可以将不同优先级的业务报文映射到不同的队列上,从而实现对不同优先级的报文提供不同的Buffer分配方案。
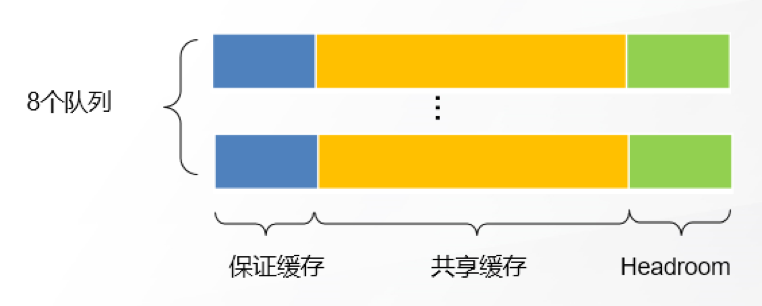
▲ 队列Buffer的组成部分
具体到每个队列,其Buffer分配根据使用场景设计为3部分:保证缓存,共享缓存,Headroom。
- 保证缓存:每个队列的专用缓存,确保每个队列均有一定缓存以保证基本转发;
- 共享缓存:流量突发时可以申请使用的缓存,所有队列共享;
- Headroom:在触发PFC水线后,到服务器响应降速前,还可以继续使用的缓存。
• 保证缓存设置
保证缓存是一个静态水线(固定的、独享的)。静态水线的利用率非常低,资源消耗却非常大。我们在实际部署时建议不分配保证缓存,以减少这部分的缓存消耗。这样,入方向报文直接使用共享缓存空间,可提高Buffer的利用率。
• 共享缓存设置
对于共享缓存的设置,需要采用更为灵活的动态水线。动态水线能根据当前空闲的Buffer资源,以及当前队列已使用的Buffer资源数量来决定能否继续申请到资源。由于系统中空闲共享Buffer资源与已使用的Buffer资源都是时刻变化的,因此阈值也处于不断变动中。相对于静态水线,动态水线能更灵活、有效的利用Buffer及避免造成不必要的浪费。
锐捷网络交换机支持基于动态的方式进行Buffer资源的分配,对共享缓存的设置分为11档,动态水线alpha值=队列可申请缓存量/剩余共享缓存量。队列的α值越大,其在共享缓存中可使用的百分数占比也就越高。
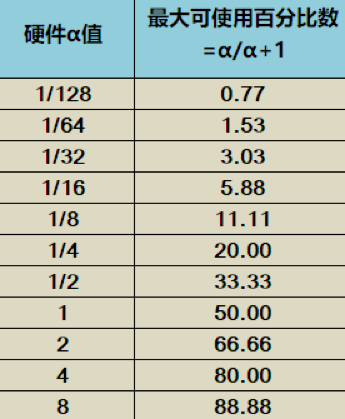
▲共享水线α值与可使用率对应关系
我们不妨分析一下:
队列的α值设置越小,其最大可申请的共享缓存占比就越小。当端口拥塞时就会越早触发PFC流控,PFC流控生效后队列降速,可以很好地确保网络不丢包。
但从性能的角度看,过早触发PFC流控,会导致RDMA网络吞吐下降。因此我们在MMU水线设置时需要选取一个平衡值。
PFC水线到底设置多少,是一个非常复杂的问题,理论上不存在一个固定的值。实际部署时,需要我们具体分析业务模型,并搭建测试环境进行水线调优,找到匹配业务的最合适的水线。
• Headroom设置
Headroom:顾名思义,就是头部空间的意思,是在PFC触发后,到PFC真正生效这一段时间,用来缓存队列报文的。Headroom设置多大合适?这里与4个因素有关:
- PG检测到触发XOFF水线,到构造PFC帧发出的时间(这里主要跟配置的检测精度以及平均队列算法相关,固定配置是固定值)
- 上游收到PFC Pause帧,到停止队列转发的时间(主要跟芯片处理性能有关系,交换芯片实际上是固定值)
- PFC Pause帧在链路上的传输时间(跟AOC线缆/光纤距离成正比)
- 队列暂停发送后链路中报文的传输时间(跟AOC线缆/光纤距离成正比)
因此Headroom所需要的缓存大小,我们可以根据组网的架构,以及流量模型测算得出。以100米光纤线 + 100G光模块,缓存64字节小包,计算出所需的Headroom大小是408个cell(cell是缓存管理的最小单元,一个报文会占用1个或者多个cell),实际测试数据也吻合。当然,考虑一定的冗余性,Headroom设置建议比理论值稍大。
RDMA网络实践
锐捷网络在研发中心搭建了模拟真实业务的RDMA网络,架构如下:
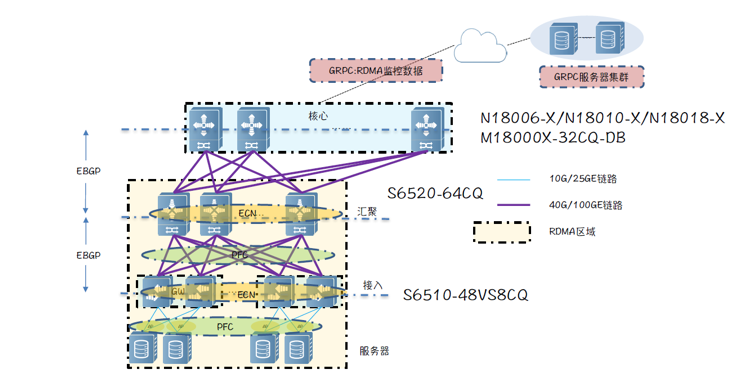
▲锐捷网络RDMA组网架构
- 组网模型:大核心三级组网架构,核心采用高密100G线卡;
- POD内:Spine采用提供64个100G接口的 BOX设备,Leaf采用提供48个25G接口+8个100G接口的BOX设备;
- Leaf作为服务器网关,支持和服务器间基于PFC流控(识别报文的DSCP并进行PG映射),同时支持拥塞ECN标记;
- RDMA仅运行于POD内部,不存在跨POD的RDMA流量,因此核心无需感知RDMA流量;
- 为了避免拥塞丢包,需要在Leaf与Spine之间部署PFC流控技术,同时Spine设备也需要支持基于拥塞的ECN标记;
- Leaf和Spine设备支持PFC流控帧统计、ECN标记统计、拥塞丢包统计、基于队列的拥塞统计等,并支持将统计信息通过gRPC同步到远端gRPC服务器。
写在最后
锐捷网络在研发中心搭建了模拟真实业务的浸泡组网环境(包括RG-S6510、RG-S6520、RG-N18000-X系列25G/100G网络设备、大型测试仪、25G服务器)。在叠加了多种业务模型,并进行了长时间浸泡测试后,我们对于RDMA网络的MMU水线设置已有一些推荐的经验值。此外,在RDMA网络中,还存在一些部署难点,比如多级网络中 PFC风暴、死锁问题、ECN水线设计复杂问题等。对于这些问题,锐捷网络也有一些研究和积累,期待与大家共同探讨。
本期作者:颜晓波
锐捷网络互联网系统部行业咨询

往期精彩回顾
●【第二期】如何通过网络遥测(Network Telemetry)技术实现精细化网络运维?
相关推荐:




,RG-S6520-64CQ")
,RG-S6510-48VS8CQ")




更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















