






技术盛宴 | 浅谈LLM推理性能的影响因子——HBD Size
作为GenAl时代的全栈服务专家,锐捷网络致力于为企业提供覆盖laaS到PaaS的全栈产品及解决方案。






随着LLM(大语言模型)技术的飞速发展,市面上出现越来越多的AGI应用,对话式机器人作为最普遍的应用已经深入普罗大众的工作和学习中。最显著的改变就是从搜索引擎查询问题,转变为打开多款对话式机器人的APP进行查询,然后再综合多个解答进行自己的判断。
那么,“对话式机器人”这类应用是如何根据用户的输入,来进行有逻辑的高质量内容输出的呢?其本质是:先通过大量的“训练”任务使其具备能够理解用户语言、逻辑和思维的能力,再通过用户给出的输入进行“推理”运算,进而输出对应的内容与用户进行高质量互动。
一、训练与推理的关系
LLM(大型语言模型)的训练和推理是模型生命周期中的两个关键阶段,我们可以类比成理论学习和应用实践的结合。
1.训练阶段(学习阶段):
该阶段是模型构建的基础,决定了模型的质量和应用效果。
1)在训练阶段,LLM通过大量的文本数据学习语言的模式、语法、语义和上下文信息。
2)使用深度学习技术,如神经网络,模型在训练过程中不断优化其参数,以提高对文本数据的建模能力。
2.推理阶段(应用阶段):
该阶段不涉及参数更新,将训练学到的知识应用到实际问题上。
1)推理阶段是指使用训练好的模型对新的输入数据进行处理,以生成输出或做出决策的过程。
2)在推理过程中,模型会接收新的文本输入,预测或生成文本,执行翻译,或者完成其他特定的NLP任务。
3.差异性:
1)目标:训练和推理都旨在实现模型的最佳性能,但训练侧重于学习,推理侧重于应用。
2)可用性:训练阶段的效果会直接影响推理阶段结果的可用性。
3)资源消耗:训练通常需要大量的计算资源和数据,而推理则更注重实时性、成本和可扩展性。
4)持续学习:推理阶段的反馈可以用于改进模型,通过持续学习或增量学习的方式,使模型适应新的数据和场景。
二、推理的过程
主流 LLM 基本都是 Decoder Only 的 Transformer 模型,推理过程可以分为两个阶段:
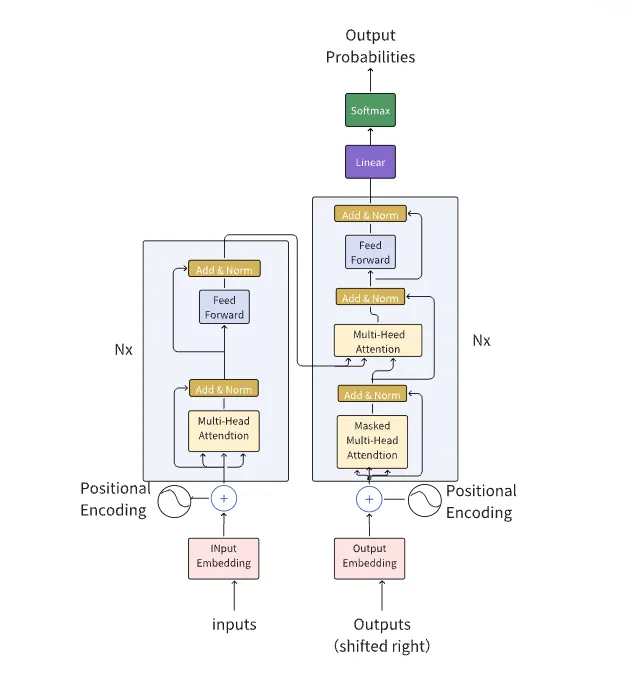
Transformer 模型结构图
1.“预填充(Prefill)”阶段:
Prefill阶段是模型根据用户输入的Tokens通过一次前向传播来生成第一个输出 Token。在前向传播过程中,输入的Tokens之间以并行方式执行运算,所以具备比较高的执行效率。
2.“解码(Decoding)”阶段:
在Prefill阶段生成第一个 Token(A)之后开始进入Decoding阶段。在Decoding阶段中,解码器会以自回归的方式逐个生成输出序列的词元。在每一步,它基于已生成的词元和之前的状态来预测下一个词元,直到生成一个特殊的 Stop Token(或者满足用户设置的某个限制条件,比如超过一定的长度) 生成过程就会停止。Decoding阶段需要执行多次前向传播,而且只能以串行的方式执行,因此效率相对比较低。
两个阶段对算力芯片的要求也不同,Prefill阶段为计算密集型,适合选用高算力 GPU;Decoding阶段为访存密集型,相应的可以使用算力不是特别强而访存带宽比较大的 GPU。
三、推理的评估指标
针对 LLM 推理服务通常有两种调用模式,如下表所述:
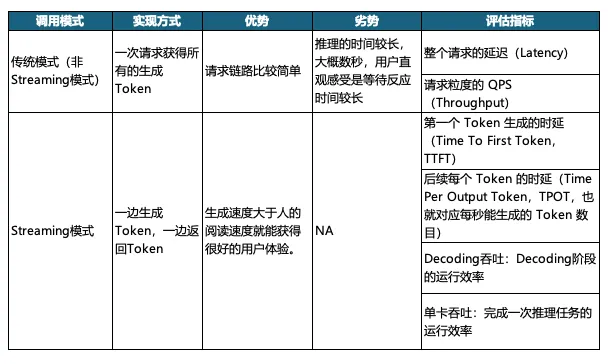
类似ChatGPT 一样的 Streaming 方式,目前应用比较广泛,主要因为可以给用户带来更好的交互体验,不需要长时间等待即可获得系统反馈,因此本文以Streaming模式下的评估指标来进行分析。
1.首个词元生成时间(Time To First Token,简称TTFT):
在用户输入查询的内容后,模型生成第一个输出token所需要的时间。
2.单个输出词元的生成时间(Time Per Output Token,简称TPOT):
推理系统根据用户请求生成后续词元所需要的平均时间。在人机实时交互的过程中,让用户得到快速的响应至关重要,延时较高会让客户陷入较长的等待时间,大大影响交互体验,但只要生成速度大于人类的阅读速度就能获得很好的用户体验。
3.Decoding吞吐:
通常用来衡量推理服务器在decoding阶段的输出效率,即decoding阶段的所有Token数量除以该阶段所需要的耗时。
4.单卡吞吐:
通常用来衡量推理服务器完成本次推理任务的输出效率,即在Prefill阶段以及decoding阶段总共生成的Token数量除以整个推理任务所需要的耗时。
四、推理性能的影响因素
影响LLM推理性能的因子有许多,本文重点分析不同HBD Size域在不同集群规模以及不同计算精度下对推理性能的影响。
1.计算精度:
指浮点数(Floating Point Numbers)的不同精度,比如FP16、FP8、FP4。
2.实例规模:
完成本次推理任务所需要的GPU卡数量。
3.HBD (High Bandwidth Domain)Size:
一个推理实例内,通过独立的高速通道形成全联接的GPU卡的数量。(跨服务器通过交换柜互联也算同一个HBD)
我们基于理论建模的和仿真算法,通过控制变量的对比方式,在保证单一因子变化的前提下去分析计算精度、集群规模以及HBD Size对推理性能的影响。
测试模型采用B200算力卡进行模拟仿真,基于QWen 110B的基础上扩展16个MoE专家,Batch Size为16,Token输入序列为32K,同时假设HBD内通过1.8TB/s的双向带宽互联。
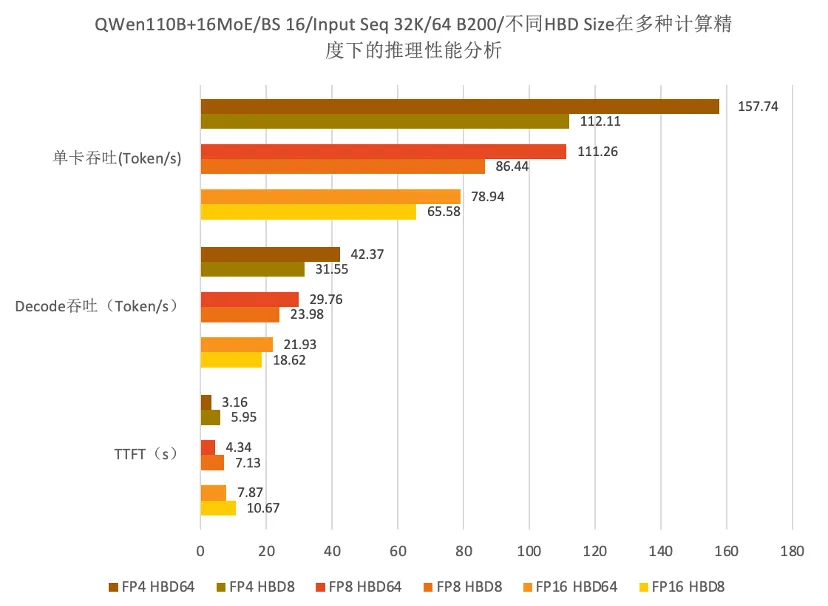
如上图数据所示,发现以下现象:
64张B200的GPU卡规模下,组成该推理实例时。在上述模型推理中,HBD Size从8提升至64,TTFT最大下降46%,单卡吞吐最大提升41%。
因此可以得出结论:HBD Size对推理性能有正面作用,即高速互联的GPU卡数量越多,推理性能越强。
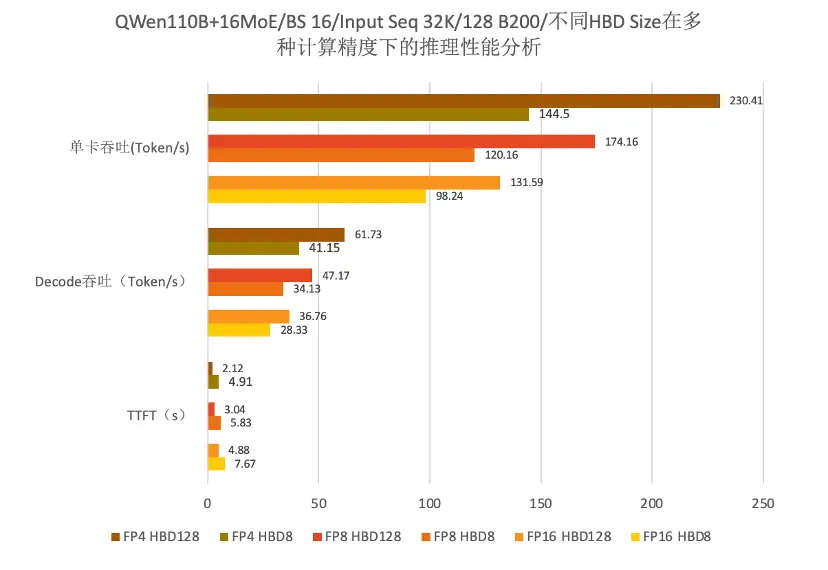
如上图数据所示,发现以下现象:
128张B200卡的GPU规模组成推理实例时,在上述模型推理中,HBD Size从8提升至128,TTFT最大下降57%,单卡吞吐最大提升59%;同样证明HBD Size的提升对推理性能有正面作用。
对比上述两份数据,发现以下现象:
从64卡扩展到128卡规模时,TTFT指标从下降46%变化为下降57%,收益更明显;再如单卡吞吐从提升41%变化为提升59%,收益更明显。
因此可以得出结论:当采用更大规模GPU卡时,HBD Size扩增时性能收益提升趋于明显。
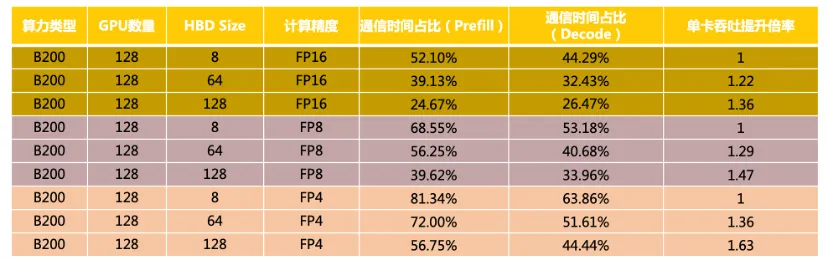
从上述表格数据中,我们发现以下现象:
同为128卡规模下,FP16精度下随着HBD Size提升,Prefill与Decoding阶段的通信时间占比逐步下降,这种现象在FP8和FP4精度下也同样存在。
当采用更低计算精度时,FP16精度下从8卡提升到128卡,单卡吞吐提升倍率为1.36;而在FP4精度下从8卡提升到128卡,单卡的吞吐提升倍率为1.63。
因此可以得出结论:在更低的计算精度下,HBD Size扩增时性能收益提升趋于明显。
五、结论
1、在相同集群规模和同样的计算精度下,随着HBD Size的提升,推理性能也随之提升。具体表现为TTFT降低,Decoding吞吐及单卡吞吐提升。
2、在相同计算精度下,集群规模越大,HBD Size的提升收益愈发明显。具体表现为TTFT降低幅度更大,Decoding吞吐及单卡吞吐提升幅度更大。
3、在相同集群规模下,计算精度越低,HBD Size的提升收益愈发明显。具体表现为Prefill与Decoding阶段的通信时间占比逐步下降幅度越慢,单卡吞吐提升倍率幅度越大。
锐捷网络,作为GenAI时代的全栈服务专家,致力于为企业提供覆盖IaaS到PaaS的全栈产品及解决方案。我们的产品覆盖高性能网络与GPU算力优化调度,旨在通过创新技术解决方案,帮助客户实现生产效率的飞跃与运营成本的优化。我们坚信,通过我们的努力,能够为客户打造一个更加智能、高效和可靠的未来。让我们携手,共同探索GenAI时代的每一个机遇。
相关标签:


点赞


更多技术博文
-

 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
















