




您订阅的产品有更新,请及时查阅
查看详情您订阅的产品有更新,请及时查阅
查看详情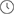 发布时间:2023-03-20
发布时间:2023-03-20

AIGC(AI-Generated Content,人工智能生产内容)近期发展迅猛,迭代速度更是呈现指数级的爆发式增长。其中,GPT-4和文心一言的推出引起了人们对其商业价值和应用场景的高度关注。随着AIGC的发展,训练模型参数规模从千亿到万亿级别,底层GPU支撑规模也达到了万卡级别。由此导致的网络规模不断增大,网络节点间通信面临着越来越大的挑战。在此背景下,如何提升AI服务器计算能力和组网通信能力并兼顾成本,已成为当前人工智能领域的重要研究方向之一。
锐捷网络针对AIGC算力、GPU利用率与网络的关系,以及主流HPC组网面临的挑战,推出了业界先进的“智速”DDC(Distributed Disaggregated Chassis,分布式分散式机箱)高性能网络方案,为AIGC业务打通“任督二脉”,助力算力突飞猛进。
锐捷网络DDC产品连接方式示意图
以ChatGPT为例,在算力方面,使用微软Azure AI超算基础设施(由10000块 V100 GPU组成的高带宽集群)上进行训练,总算力消耗约3640PF-days(即每秒一千万亿次计算,运行3640天),这里做个公式换算一下10000块V100需要训练多久:

ChatGPT算力和训练时间表
注:ChatGPT算力需求为网上获取,在此仅供参考。OpenAI 在他们的文章“AI and Compute”中假设利用率为 33%。NVIDIA、斯坦福和微软的一组研究人员在分布式系统上训练大型语言模型的利用率达到了 44% 到 52%。

ChatGPT关于训练时间的回答
根据ChatGPT的回复来看,比较符合上面表格计算出来的时间,利用率应该会在50%左右。
可以看出影响一个模型的训练时长主要因素在于GPU的利用率,以及GPU集群处理能力。而这些关键指标又与网络效率密切相关。网络效率是影响AI集群中GPU利用率的一个重要因素。在AI集群中,GPU通常是计算节点的核心资源,因为它们可以高效地处理大规模的深度学习任务。然而,GPU的利用率受到多个因素的影响,其中网络效率是一个关键因素。
网络在AI训练中扮演着至关重要的角色。AI集群通常由多个计算节点和存储节点组成,这些节点需要频繁地进行通信和数据交换。如果网络效率低下,这些节点之间的通信将会变得缓慢,这将直接影响到AI集群的算力。
低效的网络可能导致以下问题,从而降低GPU利用率:
数据传输时间增加:在低效的网络中,数据传输的时间将会增加。当GPU需要等待数据传输完成后才能进行计算时,GPU利用率将会降低;
网络带宽瓶颈:在AI集群中,GPU通常需要频繁地与其他计算节点进行数据交换。如果网络带宽不足,GPU将无法获得足够的数据进行计算,从而导致GPU利用率降低;
任务调度不均衡:在低效的网络中,任务可能会被分配到与GPU不同的计算节点上。当需要大量的数据传输时,这可能会导致GPU闲置等待,从而降低GPU利用率。
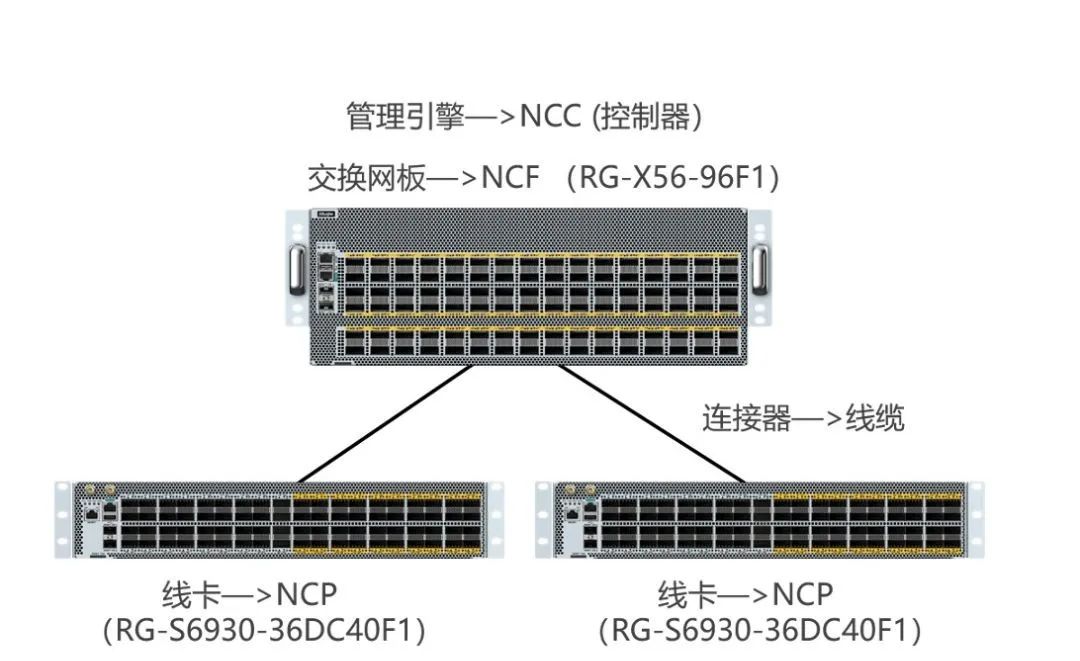
为了提高GPU利用率,需要优化网络效率。这可以通过采用更快的网络技术、优化网络拓扑结构、合理配置带宽等方法来实现。在训练模型中,分布式训练的并行度:数据并行、张量并行与流水并行决定了GPU处理的数据之间的通信模型。模型之间的通信效率受到以下几个因素的影响:
影响通信的因素
其中,带宽和设备转发时延受到硬件限制,端处理时延受技术选择(TCP or RDMA)影响,RDMA会更低,排队和重传则受到网络优化和技术选择的影响。
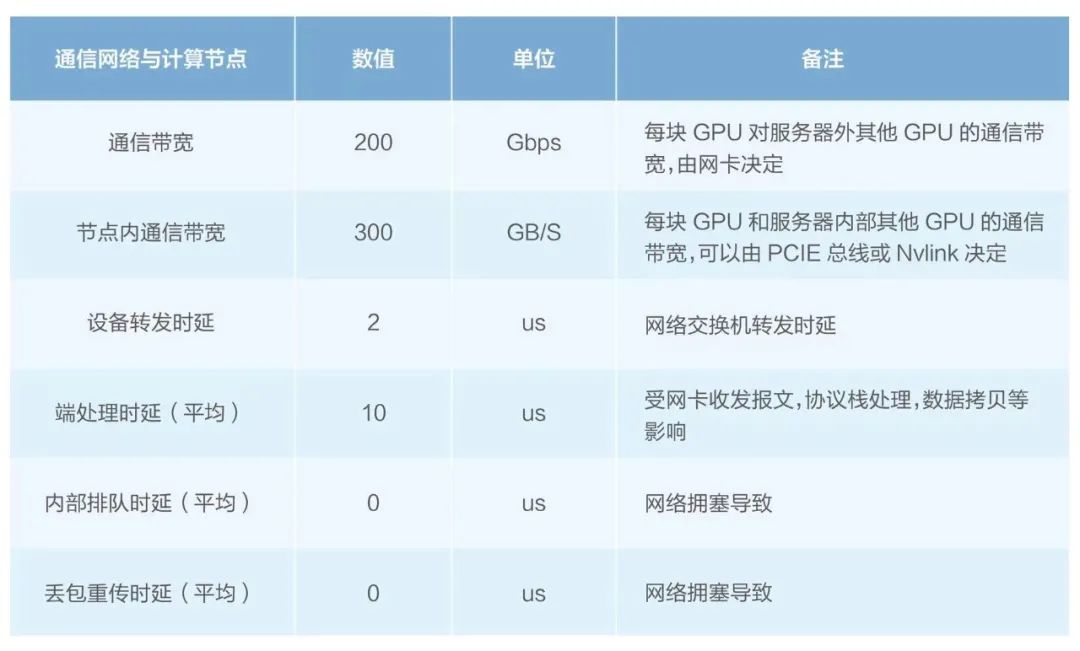
根据量化模型[1]:GPU利用率 = GPU内迭代计算时间/(GPU内迭代计算时间+网络总体通信时间)来计算得出以下结论:
带宽吞吐与GPU利用率的曲线图 动态时延和GPU利用率的曲线图
可以看到网络带宽吞吐、动态时延(拥塞/丢包)对GPU利用率影响明显。
根据通信总时延的构成来看:
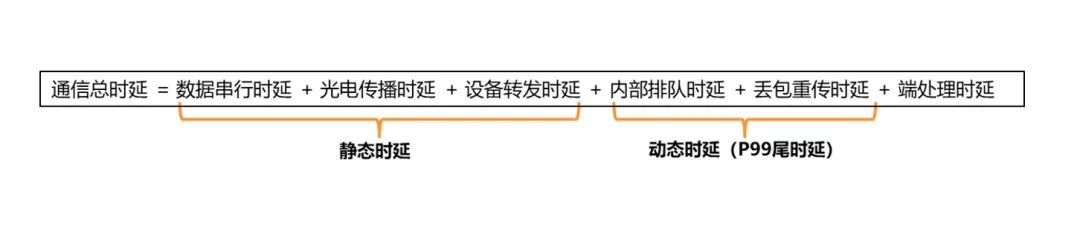
通信总时延构成图
静态时延相较之下影响更小,所以更应该着重去考虑如何减少动态时延,这样可以有效的提升GPU的利用率,从而达到提升算力的目标。
Infiniband组网是当前高性能网络的效果最优解,利用超高带宽和基于Credit的机制确保无拥塞和超低时延,但是也是最昂贵的解法,相比同带宽下传统以太网的组网会贵数倍。同时Infiniband技术封闭,业内目前成熟供应商仅1家,对于最终用户来说,无法实现第二货源。
所以业内大多数用户会选择传统以太网组网的方案。
当前高性能网络主流组网方案是基于RoCE v2来组建支持RDMA的网络。其中重要的两项搭配技术是PFC和ECN,两者均是为了避免链路中的拥塞而产生的技术。
多级PFC组网下会针对交换机入口(Ingress)拥塞,逐级反压到源端服务器暂停发送,缓解网络拥塞,规避丢包;但该方案在多级组网下可能会面临PFC Deadlock导致RDMA流量停止转发的风险。
图片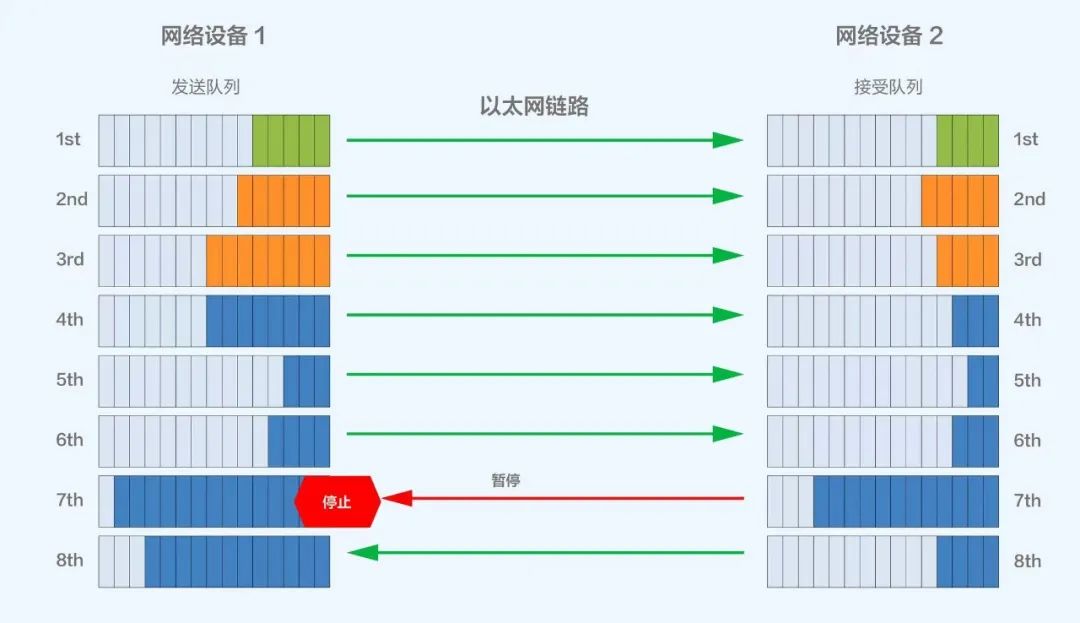
PFC工作机制示意图
而ECN则会基于对交换机出口(Egress)拥塞的目的端感知,直接生成一个RoCEv2 CNP包通知源端降速,源服务器收到CNP报文,精准降低对应QP的发送速率,缓解拥塞的同时避免无差别降速。
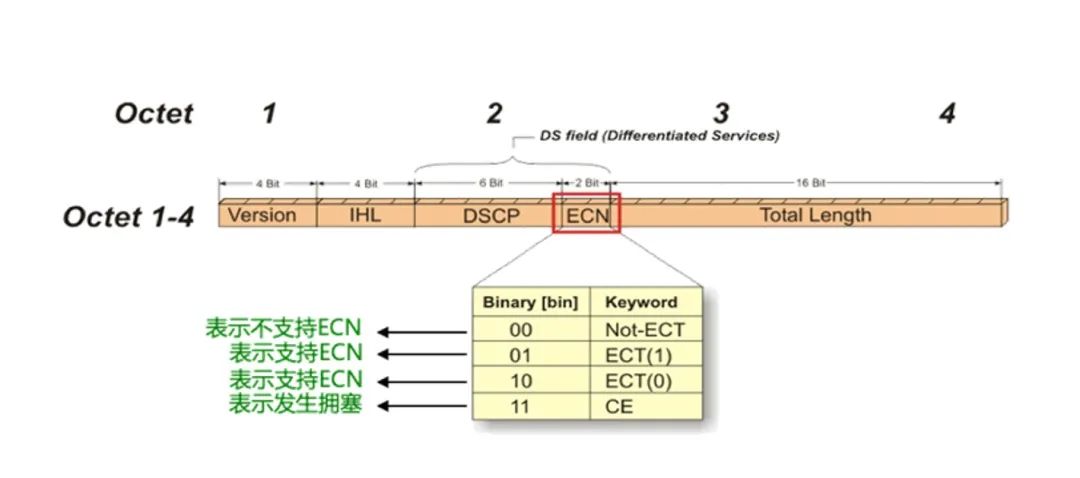
ECN标记位示意图
这两项技术本身并没有什么问题,都是为了解决拥塞而诞生的技术,但是采用这种技术后可能会被网络中可能产生的拥塞而频繁触发,最终会导致源端暂停或降速发送,通信带宽会降低,会对GPU利用率产生比较大的影响,从而造成整个高性能网络的算力被拉低。
在AI训练计算中会有All-Reduce和All-to-All两种主要的模型,两种模型都需要频繁的从一个GPU到另外多个GPU进行通信。
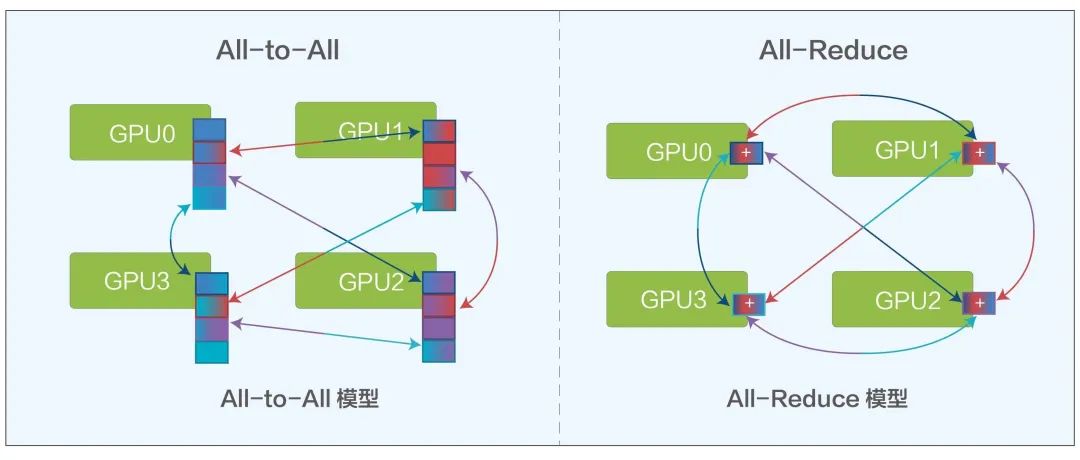
All-to-All模型 All-Reduce模型
在传统组网下,ToR和Leaf设备采用路由+ECMP的组网模式,ECMP会基于流进行哈希负载选路,有一种极端情况就是某一条ECMP链路因为一条大象流而跑满,其余多条ECMP链路相对空闲,造成负载不均的情况。
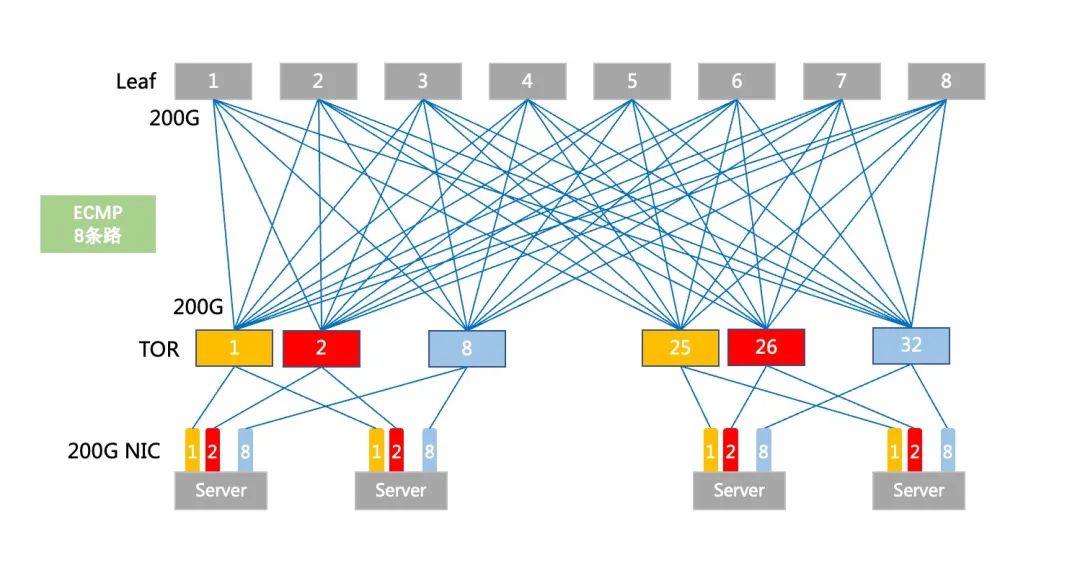
传统ECMP部署图
在内部模拟8条ECMP链路的测试环境下,测试结果如下:
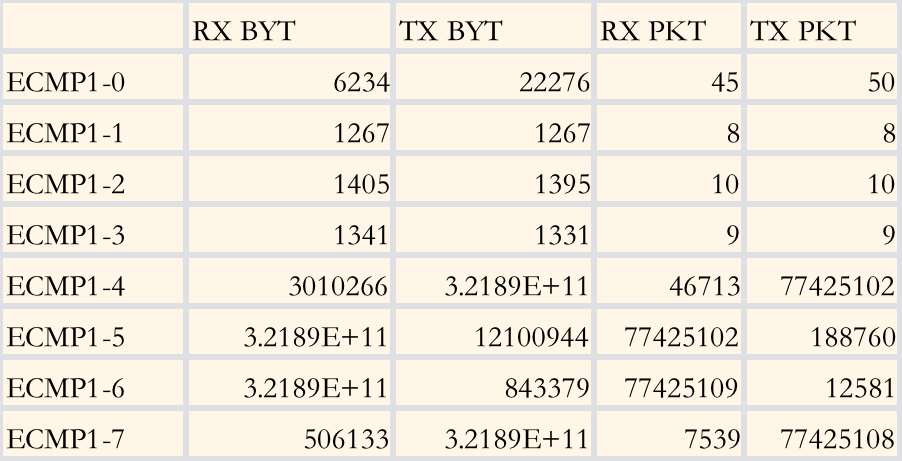
ECMP流量测试结果
可以看出,基于流的ECMP会造成较明显的某几条链路占用(ECMP1-5和1-6)和空闲(ECMP1-0至1-3较空闲),而在All-Reduce和All-to-All的两种模型下, 就很容易造成一条路线因为ECMP的负载不均而拥塞,一旦拥塞造成重传,就会提升总体的通信总时延,从而降低GPU利用率。
所以,为了解决此类问题,研究界提出了phost、Homa、NDP、1RMA 和 Aeolus等丰富的解决方案,它们在不同程度上解决了 incast, 还解决了负载平衡和低延迟请求/响应流量的问题。但是也带来了新的挑战,往往这些研究的方案都是需要端到端来解决问题,对主机、网卡、网络的改动较大,对于一般用户而言,成本较高。
海外有部分互联网公司寄希望于利用采用DNX芯片支持VOQ技术的框式交换机来解决负载不均衡带来的带宽利用率低的问题,但也面临以下几个挑战。
扩展能力一般,机框大小限制了最大端口数,如想做更大规模的集群,需要横向扩展多个机框,也会产生多级PFC和ECMP的链路,所以框只适合于小规模部署;
设备功耗大,机框内线卡芯片、Fabric芯片、风扇等数量众多,单设备的功耗极大,轻松超过2万瓦,有的甚至3万多瓦,对机柜电力要求高;
单设备端口数量多,故障域大。
所以基于以上原因,框式设备只适合小规模部署AI计算集群。
DDC是一种分布式解耦机框设备的解决方案,采用的芯片和关键技术与传统框式交换机几乎相同,但DDC架构简单支持弹性扩展和功能快速迭代、更易部署、单机功耗低。
如下图所示,业务线卡作为前端成为NCP角色,交换网板作为后端成为NCF角色,原先两者之间的连接器组件现在被光纤线缆代替,原有框式设备的管理引擎在DDC架构中也成为了NCC集中/分布式的管理组件。
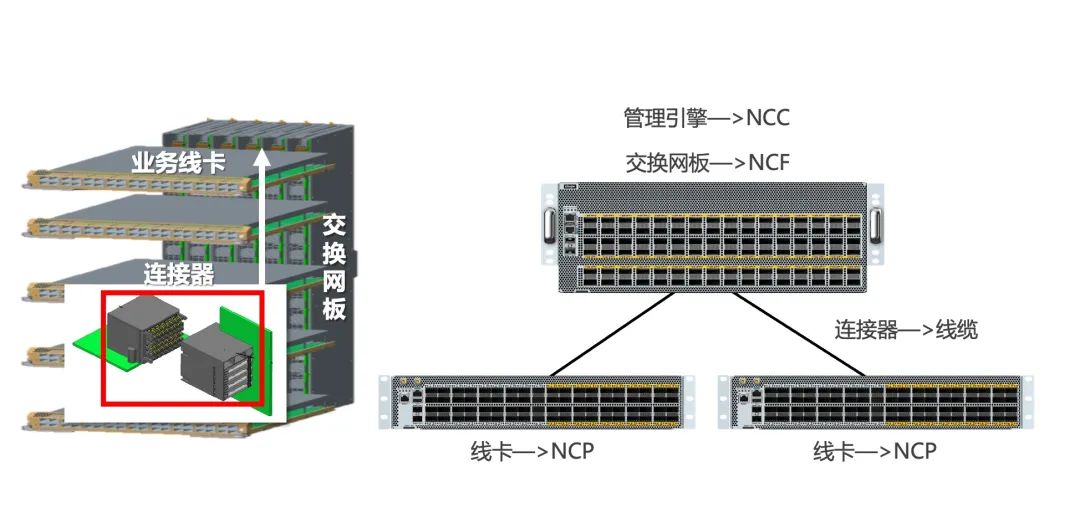
DDC产品连接方式示意图
DDC架构相较于框式架构的优势在于可以提供弹性可扩展性,组网规模可以根据AI集群大小来灵活选择。
单POD组网中,采用96台NCP作为接入,其中NCP下行共36个200G接口,负责连接AI计算集群的网卡。上行共40个200G接口最大可以连接40台NCF,NCF提供96个200G接口,该规模上下行带宽为超速比1.1:1。整个POD可支撑3456个200G网络接口,按照一台服务器配8块GPU来计算,可支撑432台AI计算服务器。
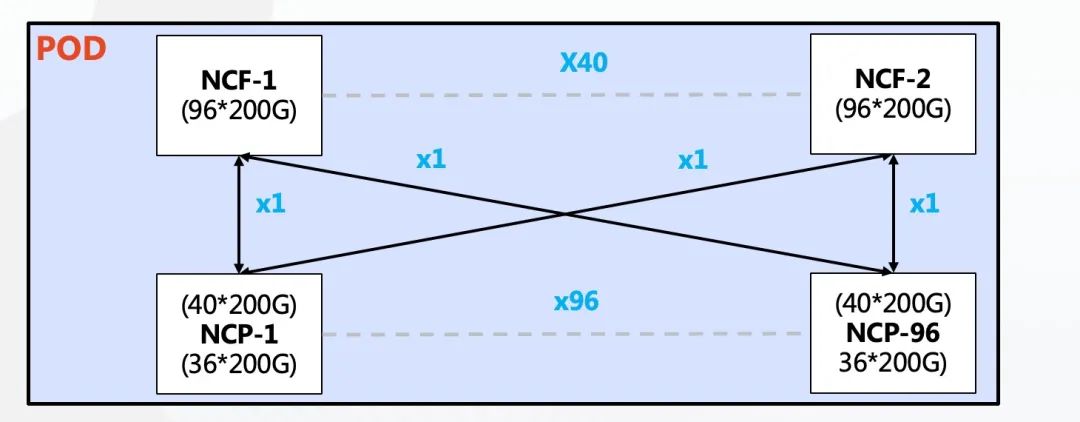
单POD组网架构图
多级POD组网中,可以实现基于POD的按需建设。因为该场景POD中NCF设备要牺牲一半的SerDes用于连接第二级的NCF,所以此时单POD采用48台NCP作为接入,下行共36个200G接口,单POD内可以支撑1728个200G接口。通过横向增加POD实现规模的扩容,整体最大可支撑10368多个200G网络端口。
NCP上行40个200G接POD内40台NCF,POD内NCF采用48个200G接口下行,48个200G接口分为16个一组上行到第二级的NCF。第二级NCF采用40个平面,每个平面3台的设计,分别对应在POD内的40台NCF。
整个网络的POD内实现了超速比1.1:1,而在POD和二级NCF之间实现了1:1的收敛比。

200G的网络端口兼容100G网卡接入,特殊情况下可利用1分2或1分4线缆兼容25/50G网卡。
依托分片后的Cells转发机制进行动态负载均衡,实现延迟的稳定性,降低了不同链路的带宽峰值差。
转发流程如图所示:
首先发送端从网络中接收数据包并分类到VOQs中存储,在发送数据包之前会先发送Credit报文确定接收端是否有足够的缓存空间处理这些报文;
如果可以则将数据包分片成Cells并且动态负载均衡到中间的Fabric节点。这些Cells在接收端会进行重组和存储,进而转发到网络中。

Cells是基于数据包的切片技术,一般大小为 64-256Byte。
切片后的Cells根据reachability table 中 cell destination 的查询来决定如何转发,并采用轮询的机制发送。这样做的好处相比ECMP按流进行哈希计算后选择某一条路的模式,切片后的Cells负载会充分利用到每一条上行链路,所有上行链路的传输数据量会近似相等。

如果接收端暂时没能力处理报文,报文会在发送端的VOQ中暂存,并不会直接转发到接收端导致丢包问题的产生,每片DNX芯片可以提供芯片内OCB缓存以及片外8GB的HBM高速缓存,对200G端口相当于可以缓存150ms左右的数据。只有当对端Credit报文明确可以接受时才会发送。这样的机制下,充分利用缓存可以大幅度减少丢包,甚至不会产生丢包情况。减少数据重传,整体通信时延更稳定更低,从而可以提高带宽利用率,进而提升业务吞吐效率。

按照DDC的逻辑来看,所有NCP和NCF可以看成一台设备,所以在此网络中部署RDMA域后,只在针对服务器的接口处存在1级的PFC,不会像传统网络一样产生多级PFC的压制与死锁。另外根据DDC的数据转发机制,可在接口处部署ECN,一旦在内部的Credit和缓存机制无法支撑突发流量,可以向服务器端发送CNP报文要求降速(通常情况下在AI的通信模型下,All-to-All和All-Reduce+Cell切片可以将流量尽可能的均衡,很难出现1个端口被打满的情况,所以ECN在多数情况可以不配置)。

在管理控制平面上,为了解决管理网故障以及NCC单点故障的影响,我们取消了NCC的集中控制面,构建了分布式OS,通过SDN运维控制器通过标准接口(Netconf、GRPC等)配置管理设备,每台NCP和NCF独立管理,有独立的控制面和管理面。
从方案理论上说,DDC拥有支持弹性扩展和功能快速迭代、更易部署、单机功耗低等众多优势;但从实际角度出发,传统组网也拥有诸如市面可选品牌和产品路线较多、可支撑更大规模的集群等技术成熟带来的优势。因此在客户面临项目需求时究竟是选择更高性能的DDC,还是更大规模部署的传统组网,可以参考下面的对比及测试结果:
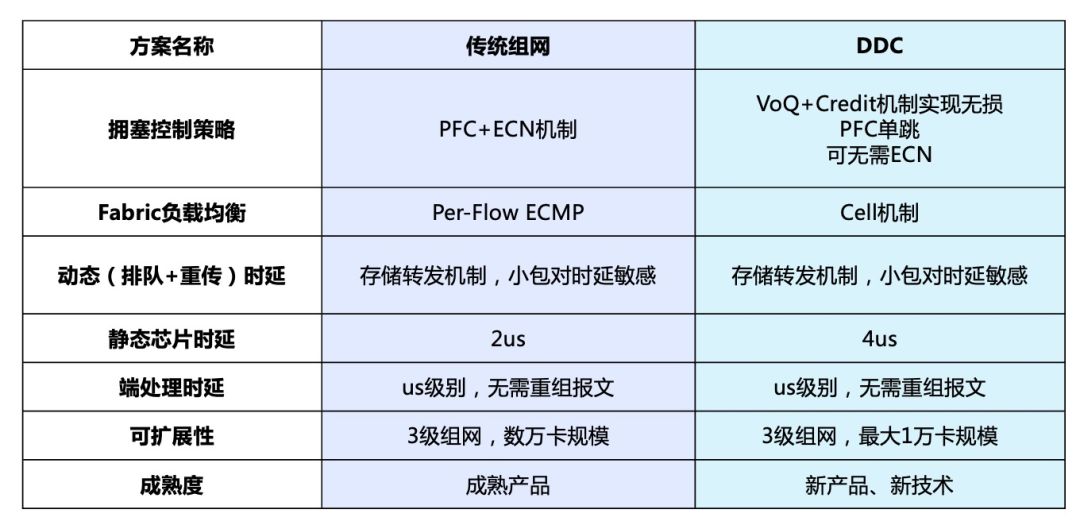
传统组网与DDC测试对比结果图
同时我们使用OpenMPI测试套件进行了框式设备(框式设备和DDC原理相同,本次采用框式测试)和传统组网设备的对比模拟测试,结论是在All-to-All场景下,相较于传统的组网,框式设备带宽利用率提升约20%(对应GPU利用率提升8%左右)。
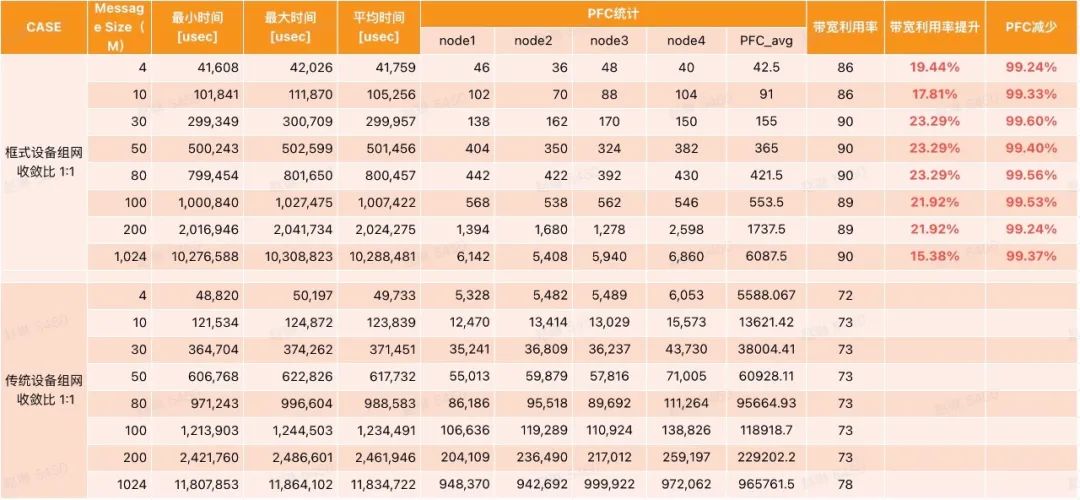
框式设备和传统组网设备的对比模拟测试
基于对客户需求的深刻理解,锐捷网络已经率先推出了两款可交付产品,分别是200G NCP交换机和200G NCF交换机。
该交换机2U高度,提供36个200G的面板口,40个200G的Fabric内联口,4个风扇和2个电源。
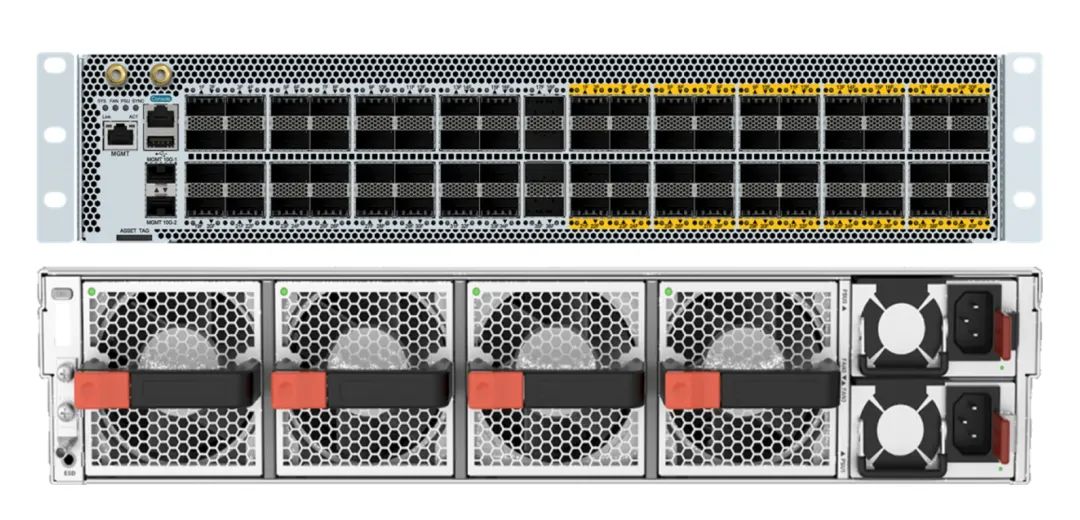
该交换机4U高度,提供96个200G的Fabric内联口,8个风扇和4个电源。

未来锐捷网络还会继续研发、推出400G端口形态产品,敬请期待。
锐捷网络(证券代码:301165)作为行业领导者,一直致力于提供高品质、高可靠性的网络设备和解决方案,以满足客户对于智算中心不断提高的需求。在推出“智速“DDC解决方案的同时,锐捷网络也在积极探索和开发传统组网中的端网优化方案,通过充分利用服务器智能网卡搭配网络设备协议的优化,实现整网带宽利用率提升,帮助客户更快迎来AIGC智算时代。
参考文献:
[1]Deepak Narayanan, Mohammad Shoeybi, Jared Casper,Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,arXiv:2104.04473v5 [cs.CL] 23 Aug 2021

 文档评价
文档评价















